2018 年から 2019 年にかけて人間超えした自然言語処理モデル#
GLUE leaderboad#
GLUE とは General Language Understanding Evaluation の abbreviation です。 最近の自然言語処理の趨勢になっています。一つのモデルで複数の課題を解くこと を マルチタスク学習 multi-task learning と呼びます。それぞれのモデルは, 最初に一般的なデータセットを用いて 事前学習 pretraining を行います。 次に,事前学習を行ったモデルに対して,複数の下流課題 downstream tasks のそれぞれに対して 詳細チューニング fine tuning を施します。これにより各下流課題ごとの 課題成績を評価します。下図は 2019 年 8 月 21 日現在の順位が示されています。
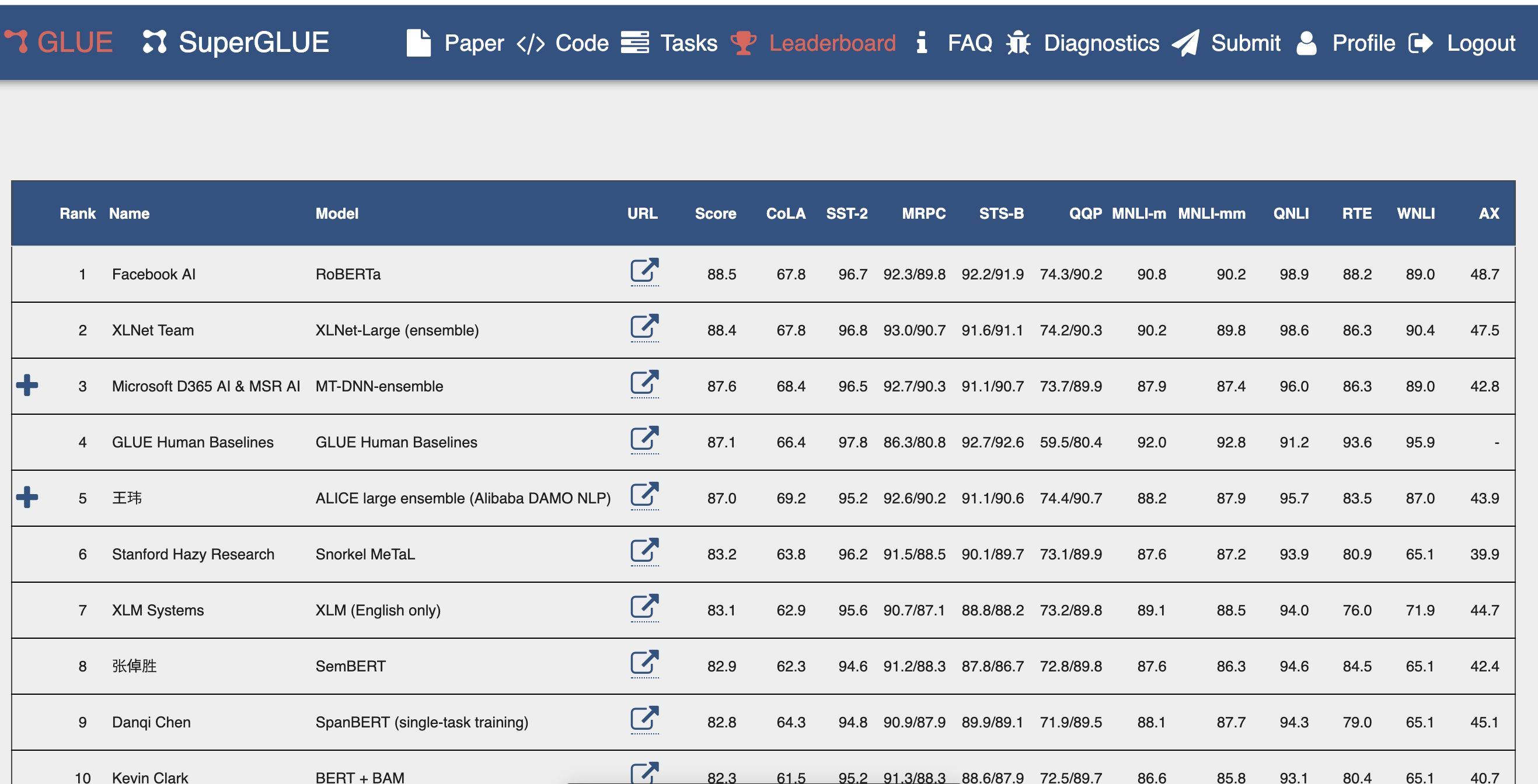
From https://gluebenchmark.com/leaderboad
この競争に参加するモデルの性能が高い順に,一行に 1 モデルが示されています。 各行のそれぞれの数字は,各下流課題の成績を示しています。上図ランキングボードによれば, 現時点でトップ成績は FAIR1 の "RoBERTa" です。 2 位は "XLNet" でグーグルと大学との合同チームです。3 位は "MT-DNN" でありマイクロソフト社と大学との堂々チームです。第 4 位は人間の成績になります。従って 1 位から 3 位までは人間の成績を凌駕した実績のモデルとなります。
GLUE: General Language Understanding Evaluation#
- MNLI: 2 つの入力文が意味的に含意,矛盾,中立を判定
- QQP: 2 つの質問文の意味が等価かを判定
- QNLI: Q and A
- SST-2: スタンフォード大による映画レビューの極性判断
- CoLA: 入力文が英語として正しいか否かを判定
- STS-B: ニュースの見出し文の類似度を5段階で評定
- MRPC: マイクロソフトの言い換えコーパスで,2つの文が等しいか否かを判定
-
RTE: MNLI に似た2つの入力文の含意を判定
-
SQuAD: スタンフォード大による Q and A ウィキペディアから抽出した文
- NER: 語の役割(人,組織,場所,その他,非 NER 語)を特定する
- SWAG: 入力文に後続する文を 4 つの選択肢から選ぶ
第2世代,すなわち1980年代からのニューラルネットワークモデルでは一度学習した内容対して 別のデータを学習させると以前学習した内容を忘れてしまうことが知られていました。
これを 壊滅的忘却 catastrophic forgetting とか 破壊的干渉 catastrophic interference と呼びました[@McCloskeyCohen1989],[@French1999]。 これに対して,画像認識でも自然言語処理でも多層のニューラルネットワークが採用されるようになり, 最終直下層 pultimate layer だけを解くべき課題ごとに入れ替えて用いることが行われます。
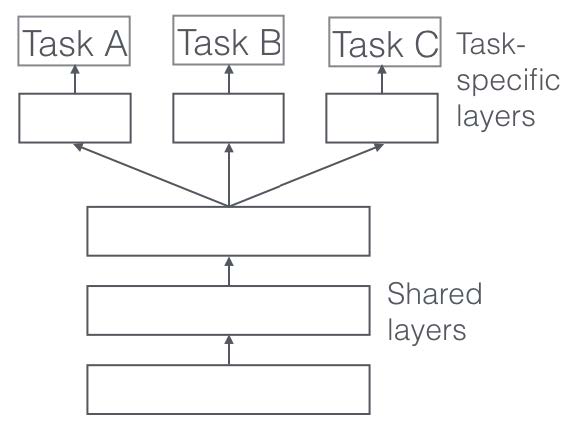
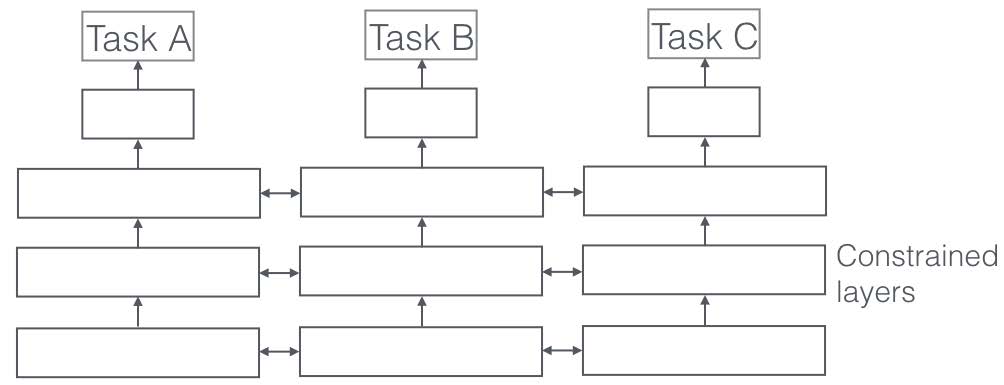
From Ruder (2017) Fig.1 and Fig2.
文献へのリンク#
- RoBERTa
- XLNet
- MT-DNN
- GPT-2
- GPT 論文
- BERT
- Transformer, 論文のタイトルは "Attention is All You Need" YouTube video
- ELMo
- ELMo blog
要約#
SOTA を達成したモデルの特徴を一言で述べます。
- RoBERTa: BERT の訓練コーパスを巨大にし,ミニバッチサイズを大きく
- XLNet: 順列言語モデル。2 ストリーム注意。
- MT-DNN: BERT ベース
- GPT-2: BERT に基づく。2019年 2 月に炎上騒ぎ
- BERT: トランスフォーマーに基づく言語モデル。マスク化言語モデル,次文予測 (but contraversial) に基づく事前訓練とファインチューニング
- ELMo: 双方向 RNN による文埋め込み
- Transformer: 自己注意に基づく言語モデル
ということですので,トランスフォーマーモデルを理解することが最近のモデルを理解する鍵になります。
トランスフォーマー (Attention is all you need)#
トランスフォーマーの特徴は
- 事前訓練として マスク化言語モデル masked language model と 次文予測 next sentence predicition をく
- 自己注意モデル


情報検索の用語 クエリ Q, キー K, バリュー 値 V,を用いている。実質 ソフトマックス あるいは 勝者占有回路 (Winners take all circuits)
数式は出しませんが注意とはソフトマックス関数です
多頭注意 multi head attention (#H=14,32,...) に基づく。各層で H の数だけ勝者が勝ち上がって来る。勝ち上がった勝者に対して同様の処理を繰り返す多層ニューラルネットワークを構成。すなわち刺激選択が注意だけに基づくので,注意がすべて と命名したと思われる
フィードフォワードネットワーク Feed Forward Networks (FFN) であるので 再帰結合 を持ちません。
トランスフォーマーでは位置情報を表現するために 位置符号器 Position Encoder (PE) と呼ばれる 仕組みを用います。
まとめると下図のようになります。

[@2017Vaswani] Fig. 1 より
BERT#
- トランスフォーマー: Attention Is All You Need(arXiv:1706.03762) で提案されたモデル。RNN のリカレント構造を注意機構だけで代替
- 事前訓練:
- マスク化言語モデル訓練
- 次文予測
実習#
TensorFlow.dev によるデモ#
BERT, GPT, and ELMo 比較#
 BERT Fig.1
BERT Fig.1
XLNet モデル 順列言語モデル#
BERT におけるマスク化言語モデルと比較検討のこと
 順列言語モデル
順列言語モデル
XLNet モデル (2) 2 ストリーム自己注意モデル#
- 2つのストリーム自己注意
- コンテンツ表現 BERT の注意と同じ , , をつかう
- クエリスト表現 コンテクスト情報 と位置情報 を用いるが当該時刻の情報 は含まない

 左: コンテンツストリーム,右: クエリストリーム
左: コンテンツストリーム,右: クエリストリーム
XLNet モデル (3)#
- BERT における位置エンコーダと比較検討のこと

"Seq2sep" 翻訳モデル#
上記の中間層の状態を素直に応用すると 機械翻訳 や 対話 のモデルになります。
下図は初期の翻訳モデルである "seq2seq" の概念図を示しました。
"<eos>" は文末 end of sentence を表します。中央の "<eos>" の前がソース言語
であり,中央の "<eos>" の後はターゲット言語の言語モデルである SRN の中間層への
入力として用います。
注意すべきは,ソース言語の文終了時の中間層状態のみをターゲット言語の最初の中間層 の入力に用いることであり,それ以外の時刻ではソース言語とターゲット言語は関係が ないことです。逆に言えば最終時刻の中間層状態がソース文の情報全てを含んでいると みなすことです。この点を改善することを目指すことが 2014 年以降盛んに行われてきました。 顕著な例が後述する 双方向 RNN, LSTM を採用したり,注意 機構を導入することでした。

From [@2014Sutskever_Sequence_to_Sequence]
Seq2seq モデルにおける注意#

Attention in natural laguage model Bahdanau et. al(2014)
-
フェイスブック人工知能研究所 Facebook AI Research のこと ↩