画像と言語との融合へ向けて#
2014 年に提案されたニューラル画像脚注付けのモデルを下図に示します。

[@2015Karpathy_FeiFei_caption]

[@2014Vinyals_Bengio_Show_and_Tell]

画像に対して注意を付加した脚注付けモデルの出力例を下図に示します。

[@2015Xu_Bengio_NIC_attention]
各画像対は右が入力画像であり,左はその入力画像の脚注付けである単語を出力している際にどこに注意しているのかを白色で表しています。
 [@2015Xu_Bengio_NIC_attention]
[@2015Xu_Bengio_NIC_attention]

Glimpse Sensor: Given the coordinates of the glimpse and an input image, the sensor extracts a retina-like representation centered at that contains multiple resolution patches.
- B) Glimpse Network: Given the location and input image , uses the glimpse sensor to extract retina representation . The retina representation and glimpse location is then mapped into a hidden space using independent linear layers parameterized by and respectively using rectified units followed by another linear layer to combine the information from both components. The glimpse network defines a trainable bandwidth limited sensor for the attention network producing the glimpse representation .
- C) Model Architecture: Overall, the model is an RNN. The core network of the model takes the glimpse representation as input and combining with the internal representation at previous time step , produces the new internal state of the model . The location network and the action network use the internal state of the model to produce the next location to attend to and the action/classification at respectively. This basic RNN iteration is repeated for a variable number of steps.[@2014Mnih_RNN_attention]
ニューヨーク・タイムズに載った NIC#
Neural Image Captioning

- Human: “A group of men playing Frisbee in the park.”
- Computer model: “A group of young people playing a game of Frisbee.”

- Human: “A young hockey player playing in the ice rink.”
- Computer model: “Two hockey players are fighting over the puck.”

- Human: “A green monster kite soaring in a sunny sky.”
- Computer model: “A man flying through the air while riding a snowboard.”

- Human: “A person riding a dirt bike is covered in mud.”
- Computer model: “A person riding a motorcycle on a dirt road.”

- Human: “Three different types of pizza on top of a stove.”
- Computer model: “A pizza sitting on top of a pan on top of a stove.”

- Human: “Elephants of mixed ages standing in a muddy landscape.”
- Model: “A herd of elephants walking across a dry grass field.”
実習ファイル#



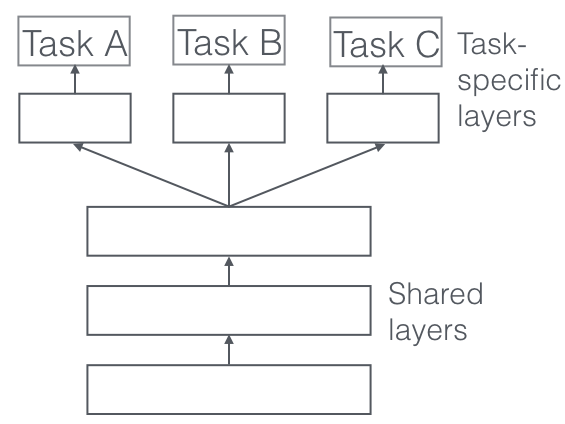
Hard parameter sharing#
左:マルチタスク学習, 右:転移学習, いずれも Sebastuan Ruder のブログより
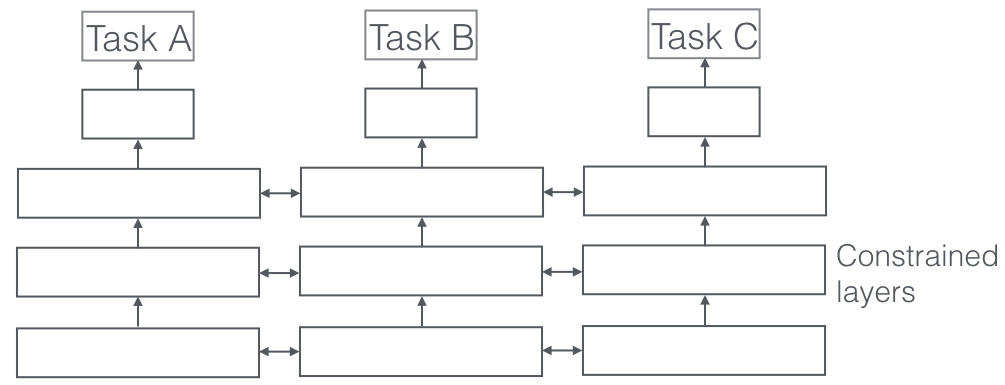
Soft parameter sharing#
In soft parameter sharing on the other hand, each task has its own model with its own parameters. The distance between the parameters of the model is then regularized in order to encourage the parameters to be similar. [8] for instance use the norm for regularization, while [9] use the trace norm.
- [8]: Duong, L., Cohn, T., Bird, S., & Cook, P. (2015). Low Resource Dependency Parsing: Cross-lingual Parameter Sharing in a Neural Network Parser. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Short Papers), 845–850.
- [9]: Yang, Y., & Hospedales, T. M. (2017). Trace Norm Regularised Deep Multi-Task Learning. In Workshop track - ICLR 2017. Retrieved from http://arxiv.org/abs/1606.04038
Recent work on MTL for Deep Learning#
Deep Relationship Networks#
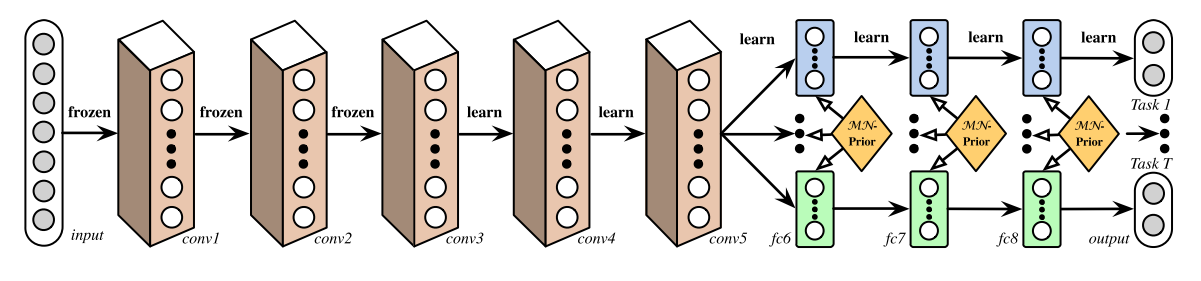 A Deep Relationship Network with shared convolutional and task-specific fully connected layers with matrix priors (Long and Wang, 2015).
A Deep Relationship Network with shared convolutional and task-specific fully connected layers with matrix priors (Long and Wang, 2015).
- Long, M., & Wang, J. (2015). Learning Multiple Tasks with Deep Relationship Networks. arXiv Preprint arXiv:1506.02117. Retrieved from http://arxiv.org/abs/1506.02117 ↩︎
Fully-Adaptive Feature Sharing#
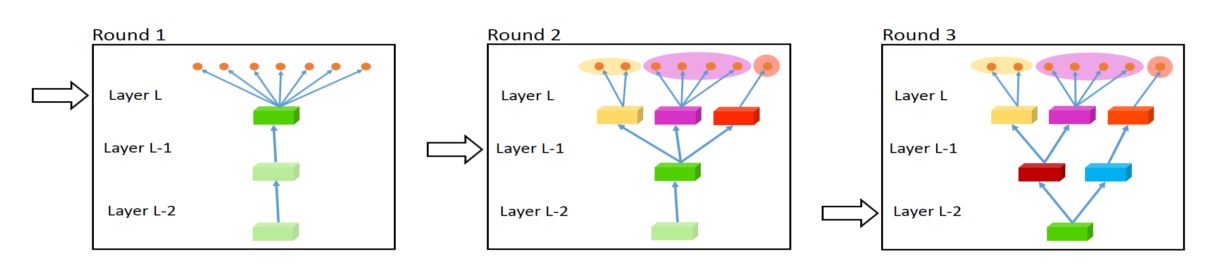
The widening procedure for fully-adaptive feature sharing (Lu et al., 2016).
Lu, Y., Kumar, A., Zhai, S., Cheng, Y., Javidi, T., & Feris, R. (2016). Fully-adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification. Retrieved from http://arxiv.org/abs/1611.05377
Cross-stitch Networks#
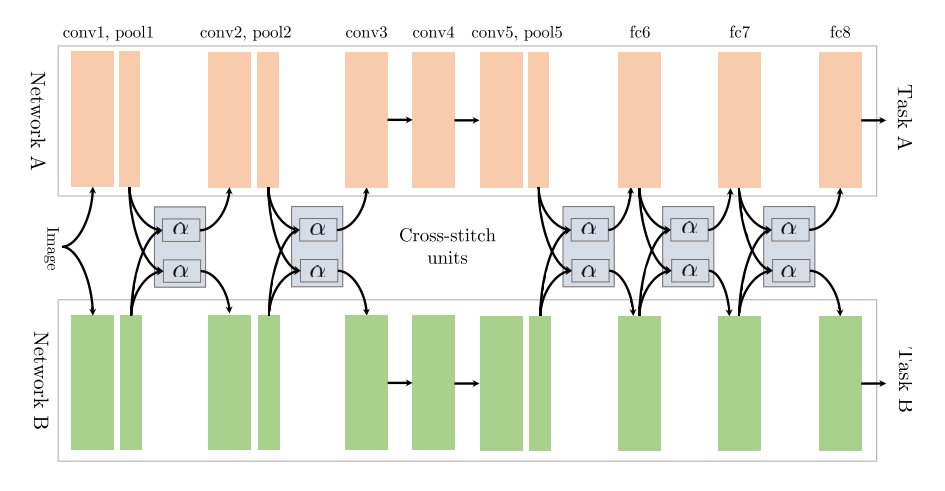
Cross-stitch networks for two tasks (Misra et al., 2016).
Misra, I., Shrivastava, A., Gupta, A., & Hebert, M. (2016). Cross-stitch Networks for Multi-task Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2016.433