Python#
Python は高級言語であり動的マルチパラダイムのプログラミング言語である。 Python のコードは強力なアイデアを数行で表現できる擬似言語に喩えられる。 例えば古典的なクイックソートアルゴリズムは Python では以下のようになる:
def quicksort(arr): if len(arr) <= 1: return arr pivot = arr[int(len(arr) / 2)] left = [x for x in arr if x < pivot] middle = [x for x in arr if x == pivot] right = [x for x in arr if x > pivot] return quicksort(left) + middle + quicksort(right) print(quicksort([3,6,8,10,1,2,1])) # 印字( "[1, 1, 2, 3, 6, 8, 10]")
Python のバージョン#
現在 Python は 2 種類のバージョンがサポートされている。2.7 系 と 3 系 である。 Python 3.0 以来,前方互換性が廃棄されて 2.7 系 と 3 系では互いに交換可能でない。 本稿全コード 2.7 で動作する。
Python のバージョンを調べるにはコマンドラインから python –version とするとチェックできる。
基本データ型#
他の多くの言語と同じくPythonには整数型, 浮動小数点型,
ブール(真偽)型, 文字列型という基本データ型がある。
これらのデータ型は他のプログラミング言語と類似している。
数値#
整数型と浮動小数点型は他言語と同様に動作する。
x = 3 print(type(x)) # 印字 "<type 'int'>" print(x) # 印字"3" print(x + 1) # 加算; 印字 "4" print(x - 1) # 減算; 印字 "2" print(x * 2) # 乗算; 印字 "6" print(x ** 2) # 指数; 印字 "9" x += 1 print(x) # 印字 "4" x *= (2) print(x) # 印字 "8" y = 2.5 print(type(y)) # 印字 "<type 'float'>" print(y, y + 1, y * 2, y ** 2) # 印字 "2.5 3.5 5.0 6.25"
他言語と異なりPythonには増分x++,減分x–を行う単項演算子は ない。
Pythonには倍精度整数,複素数型も標準実装されている。詳細は https://docs.python.org/2/library/stdtypes.html#numeric-types-int-float-long-complexに掲載されている。
ブール型(真偽型): Pythonは2値論理演算用の記号([&&]
[||], など)が用意されている。
t = True f = False print(type(t)) # 印字 "<type 'bool'>" print(t and f) # 論理積 AND; 印字 "False" print(t or f) # 論理和 OR; 印字 "True" print(not t) # 論理否定 NOT; 印字 "False" print(t != f) # 排他的論理和 XOR; 印字 "True"
文字列#
Pythonは文字列の扱いに優れる
hello = 'hello' # 文字列リテラルはシングルクォート world = "world" # あるいはダブルクォート。両方可能 print(hello) # 印字 "hello" print(len(hello)) # 文字列長の印字; 印字 "5" hw = hello + ' ' + world # 文字列連結 print(hw) # 印字 "hello world" hw12 = '%s %s %d' % (hello, world, 12) # sprintf 形式のフォーマット print(hw12) # 印字 "hello world 12"
文字列オブジェクトは有益なメソッド群である。
s = "hello" print(s.capitalize()) # 文字列の語頭の大文字化; 印字 "Hello" print(s.upper()) # 文字列の大文字化; 印字 "HELLO" print(s.rjust(7)) # 文字列の右寄せ, 空白で埋まる; 印字 " hello" print(s.center(7)) # 文字列のセンタリング,空白で埋める; 印字 " hello " print(s.replace('l', '(ell)')) # 部分文字列の置換; 印字 "he(ell)(ell)o" print(' world '.strip()) # 空白の除去; 印字 "world"
全文字列メソッドは https://docs.python.org/2/library/stdtypes.html#string-methods に記載されている。
コンテナ#
Python にはリスト,辞書,集合,タプルというコンテナが標準実装されている。
リスト#
リストは配列のPython実装であるが,サイズ可変,かつ,異なる要素を持つことが できる。
xs = [3, 1, 2] # リストの作成 print(xs, xs[2]) # 印字 "[3, 1, 2] 2" print(xs[-1]) # 負の指定子はリスト末端からの計数; 印字 "2" xs[2] = 'foo' # リストには異なる要素を含むことができる print(xs) # 印字 "[3, 1, 'foo']" xs.append('bar') # リスト末に新要素を追加 print(xs) # 印字 x = xs.pop() # リストの最終要素取り除きその値を返す print(x, xs) # 印字 "bar [3, 1, 'foo']"
上と同様に血みどろの全リストの詳細が https://docs.python.org/2/tutorial/datastructures.html#more-on-lists に記載されている。
スライス:#
Python には一旦リストにアクセスすれば,その下位リストへ簡便にアクセスする記法がある。これをスライスと呼ぶ。
nums = list(range(5)) # range は組み込み関数で整数からなるリストを生成する print(nums) # 印字 "[0, 1, 2, 3, 4]" print(nums[2:4]) # 2番目の要素から4番目未満のスライス; 印字 "[2, 3]" print(nums[2:]) # 2番目から最後までのスライス; 印字 "[2, 3, 4]" print(nums[:2]) # 先頭要素から指定子2までの要素をスライス; 印字 "[0, 1]" print(nums[:]) # リスト全体のスライスを得る; 印字 "[0, 1, 2, 3, 4]" print(nums[:-1]) # スライス指定子には負値もとることができる; 印字 "[0, 1, 2, 3]" nums[2:4] = [8, 9] # スライスして新しい値を割り当てる print(nums) # 印字 "[0, 1, 8, 8, 4]"
NumPyの配列の項においてスライシングについて再び触れることとする。
ループ:#
以下のようにリストの要素を繰り返すことができる。
animals = ['cat', 'dog', 'monkey'] for animal in animals: print(animal) # 各行に印字 "cat", "dog", "monkey"
あるループ内で各要素のインデックスを参照したければ,繰り返し内部で組み込み
関数[enumerate]を使えば良い。
animals = ['cat', 'dog', 'monkey'] for idx, animal in enumerate(animals): print('#%d: %s' % (idx + 1, animal)) # 印字行毎に "#1: cat", "#2: dog", "#3: monkey"
リスト内包表記:#
プログラミングにおいてはある型のデータを別の型へ変換した い場合が多い。自乗を計算するコードを以下に示す:
nums = [0, 1, 2, 3, 4] squares = [] for x in nums: squares.append(x ** 2) print(squares) # 印字 [0, 1, 4, 9, 16]
リスト内包表記 を使えばより簡単なコードが書ける:
nums = [0, 1, 2, 3, 4] squares = [x ** 2 for x in nums] print(squares) # 印字 [0, 1, 4, 9, 16]
辞書:#
Java の Map や Javascript のオブジェクトと同様,辞書とは,キー値とペア値を 集めたものである。
d = {'cat': 'cute', 'dog': 'furry'} # データから辞書を作成
print(d['cat']) # 辞書の項目から内容を表示; 印字 "cute"
print('cat' in d) # 辞書内を検索しキーの存在を返す; 印字 "True"
d['fish'] = 'wet' # 新項目を追加
print(d['fish']) # 印字 "wet"
# print(d['monkey']) # 辞書 d からキー'monkey'を検索。存在しないとキーエラー
print(d.get('monkey', 'N/A')) # 辞書の検索デフォルト値付き; 印字 "N/A"
print(d.get('fish', 'N/A')) # 辞書の検索デフォルト値付き; 印字 "wet"
del(d['fish']) # 辞書内の項目を削除
print(d.get('fish', 'N/A')) # "fish" は辞書にないので "N/A"
辞書についてもウェブ上に文書が掲載されている。
ループ:#
辞書のキーを繰り返す簡便法がループである:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d:
legs = d[animal]
print('A %s has %d legs' % (animal, legs))
# 印字 "A person has 2 legs", "A spider has 8 legs", "A cat has 4 legs"
辞書の各項目に対応する値を取り出すには iteritems メソッドを用いる:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal, legs in d.items():
print('A %s has %d legs' % (animal, legs))
# 印字 "A person has 2 legs", "A spider has 8 legs", "A cat has 4 legs"
辞書内包表記:#
リスト内包表記と同様,辞書内包表記にも簡便な方法が存在する。以下の例のとおり:
nums = [0, 1, 2, 3, 4] even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0} print(even_num_to_square) # 印字 "{0: 0, 2: 4, 4: 16}"
集合:#
集合とは異なる要素を持つ順番を持たないデータの集まりである。以下の例を参照:
animals = {'cat', 'dog'}
print('cat' in animals) # 集合内の要素の存在の有無のチェック; 印字 "True"
print('fish' in animals) # 印字 "False"
animals.add('fish') # 集合に要素を追加
print('fish' in animals) # 印字 "True"
print(len(animals)) # 集合の要素数を返す; 印字 "3"
animals.add('cat') # 集合に既存の要素を加えても何も起きない
print(len(animals)) # 印字 "3"
animals.remove('cat') # 集合から要素を削除
print(len(animals)) # 印字 "2"
今までと同じく,集合の全てについて記述した文書が上梓されている。
繰り返し:#
集合における繰り返しもリストに対する繰り返しと同じ記法である。 しかし集合には順序がないので,集合内の各要素について順番を仮定してはならない:
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
# 印字 "#1: fish", "#2: dog", "#3: cat"
集合内包表記:#
リストや辞書と同様,集合内包にも簡易記法が存在する:
from math import sqrt nums = {int(sqrt(x)) for x in range(30)} print(nums) # 印字 "set([0, 1, 2, 3, 4, 5])"
タプル:#
タプルとは値の順序の変更が不能な順序付きリストである。タプルはリストに類似 しているが,辞書のキーとして集合を要素として持つことが可能である。リストに はこの特徴は無い。簡単な例を示す:
d = {(x, x + 1): x for x in range(10)} # タプルキーを持つ辞書の生成
t = (5, 6) # タプルの生成
print(type(t)) # 印字 "<type 'tuple'>"
print(d[t]) # 印字 "5"
print(d[(1, 2)]) # 印字 "1"
https://docs.python.org/2/tutorial/datastructures.html#tuples-and-sequences には更に詳しい情報が記載されている。
関数#
Python の関数はキーワード def を用いて定義される。以下の例:
def sign(x): if x > 0: return 'positive' elif x < 0: return 'negative' else: return 'zero' for x in [-1, 0, 1]: print(sign(x)) # 印字 "negative", "zero", "positive"
関数は以下のようにオプションキーワード付きで定義可能である:
def hello(name, loud=False): if loud: print('HELLO, %s' % name.upper()) else: print( 'Hello, %s!' % name) hello('Bob') # 印字 "Hello, Bob" hello('Fred', loud=True) # 印字 "HELLO, FRED!"
Python のクラス情報は https://docs.python.org/2/tutorial/controlflow.html#defining-functionsを参照のこと
クラス#
Pythonにおけるクラス定義の記法は直截的である。
class Greeter: # Constructor def __init__(self, name): self.name = name # インスタンスの生成 # Instance method def greet(self, loud=False): if loud: print('HELLO, %s!' % self.name.upper()) else: print('Hello, %s' % self.name) g = Greeter('Fred') # Greeter クラスのインスタンスを生成 g.greet() # インスタンスメソッドの呼び出し; 印字 "Hello, Fred" g.greet(loud=True) # インスタンスメソッドの呼び出し; 印字 "HELLO, FRED!"
クラスについての詳細は以下である https://docs.python.org/2/tutorial/classes.html
NumPy#
NumPyはPythonにおける科学技術計算の核となるライブラリである。高性能多次元配列オブジェクトと配列処理用ツールから構成されている。MATLAB が既知ならば,本チュートリアルからNumPyを始めるのが良いだろう。
配列#
NumPyの配列は値の格子状配置である。全要素の値は同じデータ型であり,非負整数のタプルで指定可能である。
Pythonにおける配列は入れ子になったリストであり,カギカッコを用いる。
import numpy as np a = np.array([1, 2, 3]) # 次元数 1 の配列の作成 print(type(a)) # 印字 "<type 'numpy.ndarray'>" print(a.shape) # 印字 "(3,)" print(a[0], a[1], a[2]) # 印字 "1 2 3" a[0] = 5 # 配列の要素を一つ変更 print(a) # 印字 "[5, 2, 3]" b = np.array([[1,2,3],[4,5,6]]) # 次元数が 2 の配列の作成 print(b.shape) # 印字 "(2, 3)" print(b[0, 0], b[0, 1], b[1, 0]) # 印字 "1 2 4"
NumPy には配列を生成する関数が用意されている:
import numpy as np a = np.zeros((2,2)) # 全要素がゼロの配列の作成 print(a) # 印字 "[[ 0. 0.] # [ 0. 0.]]" b = np.ones((1,2)) # 全要素がゼロの配列の作成 print(b) # 印字 "[[ 1. 1.]]" c = np.full((2,2), 7) # 定数行列を作成 print(c) # 印字 "[[ 7. 7.] # [ 7. 7.]]" d = np.eye(2) # 2x2 の単位行列の作成 print(d) # 印字 "[[ 1. 0.] # [ 0. 1.]]" e = np.random.random((2,2)) # 乱数で初期化した配列の作成 print(e) # 印字例 "[[ 0.91940167 0.08143941] # [ 0.68744134 0.87236687]]"
配列を作成する他の方法はhttp://docs.scipy.org/doc/numpy/user/basics.creation.html#arrays-creationで読むことができる。
配列指定#
NumPy には指定子を配列化する方法が複数存在する。
スライス:#
Pythonにおけるリストと同様,NumPyの配列にはスライス が適用可能である。配列の各次元毎にスライスを指定可能である。
import numpy as np # 3行4列で階数が2の行列の作成 # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) # 下位行列のスライスし,上2行の1列目2列目を用いて2行2列の行列を作成 # [[2 3] # [6 7]] b = a[:2, 1:3] # スライスは元行列への参照なので,スライスへの変更は元データに影響を及ぼす print(a[0,1]) # 印字 "2" b[0, 0] = 77 # b[0, 0] は a[0, 1] と等価 print(a[0,1]) # 印字 "77"
整数指定子とスライス指定子を混在させることができる。 しかし,そうすると元行列よりも次元の低い行列を作成することになる。 MATLAB における行列スライスとは異なることに注意せよ。
import numpy as np # 3行4列の2次の行列を作成 # [[ 1 2 3 5] # [ 4 6 7 8] # [ 9 10 11 12]] a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) # 行列の中央行へのアクセス2種類 # スライスと整数の混在は階数の低下をもたらす # 一方,スライスのみを使用した場合には原行列の次元低減は発生しない row_r1 = a[1, :] # 行列 a の 2 行目の全列表示 row_r2 = a[1:2, :] # 行列 a の 2 行目の全列表示 print(row_r1, row_r1.shape) # 印字 "[5 6 7 8] (4,)" print(row_r2, row_r2.shape) # 印字 "[[5 6 7 8]] (1, 4)" # 行列に対する列への操作も同様 col_r1 = a[:, 1] col_r2 = a[:, 1:2] print(col_r1, col_r1.shape) # 印字 "[ 2 6 10] (3,)" print(col_r2, col_r2.shape) # 印字 "[[ 2] # [ 6] # [10]] (3, 1)"
整数型配列指定子:#
NumPyの配列に対してスライスを実行すると,結果は元行列の下位配列となる。 これに対して,整数型変数からなる配列に対してスライスを実行すれば, 新たな配列が構成される。以下のとおり:
import numpy as np a = np.array([[1,2], [3, 4], [5, 6]]) # 整数型配列の例 戻り値の配列の shape は (3,) print(a[[0, 1, 2], [0, 1, 0]]) # 印字 "[1 4 5]" # 上例は整数型配列を指定子とした場合と等しい: print(np.array([a[0, 0], a[1, 1], a[2, 0]])) # 印字 "[1 4 5]" # 整数型配列を指定子として用いると元配列と同じ要素を再利用できる print(a[[0, 0], [1, 1]]) # 印字 "[2 2]" # 先の整数型の配列指定子に等しい print(np.array([a[0, 1], a[0, 1]])) # 印字 "[2 2]" print(np.array([a[0, 1], a[0, 1]])) # 印字 "[2 2]"
ブーリアン配列指定子:#
ール(2値)型配列指定子は配列の任意の要素を取り 出すことが可能である。この指定子により配列から任意の条件を満たす要素からな る配列を作成することが可能である。
import numpy as np a = np.array([[1,2], [3, 4], [5, 6]]) bool_idx = (a > 2) # 2 より大きい配列の要素を探す # これにより numpy の配列と等しい shape でブール型の # 配列を返す。bool_idx は a の各要素が 2 より大きい # か否かを示す print(bool_idx) # 印字 "[[False False] # [ True True] # [ True True]]" # ブール型配列指定子を用いて階数1の行列を作ることができる # bool_idx の True に対応する要素で構成される行列である print(a[bool_idx]) # 印字 "[3 4 5 6]" # 上例を簡潔に表記可能である print(a[a > 2]) # 印字 "[3 4 5 6]"
本稿の簡潔性ゆえNumPyの配列指定子の詳細については多くを記載していない。 詳細は文献を参照のこと。
データ型#
NumPy の配列は同じ型の要素からなるグリッドである。 配列作成には一連のデータ型を利用可能である。 NumPyは配列のデータ型が何であるかを類推しようとする。 以下のようにオプション引数により明示的に配列のデータ型を指定することも可能である:
import numpy as np x = np.array([1,2]) # numpy にデータ型を選択させる print(x.dtype) # 印字 "int64" x = np.array([1.0, 2.0]) # numpy にデータ型を選択させる print(x.dtype) # 印字 "float64" x = np.array([1, 2], dtype=np.int64) # データ型の強制指定 print(x.dtype) # 印字 "int64"
NumPy の全データ型についてはhttp://docs.scipy.org/doc/numpy/reference/arrays.dtypes.htmlを参照のこと。
数学的配列#
基本的数学関数の操作は配列の要素毎の演算である。 NumPy モジュールの関数として演算子を上書き可能である.
import numpy as np x = np.array([[1,2],[3,4]], dtype=np.float64) y = np.array([[5,6],[7,8]], dtype=np.float64) # 対応する要素の和,両例とも同じ結果を得る # [[ 6.0 8.0] # [10.0 12.0]] print(x + y) print(np.add(x, y)) # 対応する要素の差,両例とも同じ結果を得る # [[-4.0 -4.0] # [-4.0 -4.0]] print(x - y) print(np.subtract(x, y)) # 対応する要素の積,両例とも同じ結果を得る # [[ 5.0 12.0] # [21.0 32.0]] print(x * y) print(np.multiply(x, y)) # 対応する要素の徐,両例とも同じ結果を得る # [[ 0.2 0.33333333] # [ 0.42857143 0.5 ]] print(x / y) print(np.divide(x, y)) # 各要素の平方根 # [[ 1. 1.41421356] # [ 1.73205081 2. ]] print(np.sqrt(x))
MATLAB と異なり,[*]
は要素毎の積であり,行列の積ではない。
ベクトルの内積,ベクトルと行列の積,行列の積には[dot]を用いる。
[dot]は NumPy モジュールと配列オブジェクトのメソッドインスタンスに
適用可能である。
import numpy as np x = np.array([[1,2],[3,4]]) y = np.array([[5,6],[7,8]]) v = np.array([9,10]) w = np.array([11, 12]) # ベクトルの内積両者とも同じく 219 を得る print(v.dot(w)) print(np.dot(v, w)) # 行列とベクトルの積。両者とも同じく [29 67] を得る print(x.dot(v)) print(np.dot(x, v)) # 行列と行列の積。両者とも同じく以下の行列を得る # [[19 22] # [43 50]] print(x.dot(y)) print(np.dot(x, y))
NumPy は行列操作遂行に有役な関数を数多く提供している。[sum]
など
import numpy as np x = np.array([[1,2],[3,4]]) print(np.sum(x)) # 総和を計算 10と印字 print(np.sum(x, axis=0)) # 各列の総和を計算: "[4 6]" と印字 print(np.sum(x, axis=1)) # 各行の総和を計算: "[3 7]" と印字
NumPyの全数学関数リストは http://docs.scipy.org/doc/numpy/reference/routines.math.htmlから入手可 能である。
配列を用いた数学関数の計算だけでなく,配列の reshae
や他のデータ操作が多数必
要となる。単純な例は行列の転置である。行列の転置には配列オブジェクトの
[T] を使えばよい。
import numpy as np x = np.array([[1,2], [3,4]]) print(x) # 印字 "[[1 2] # [3 4]]" print(x.T) # 印字 "[[1 3] # [2 4]]" # 階数1の行列を転置してもなにも変わらないことに注意 v = np.array([1,2,3]) print(v) # 印字 "[1 2 3]" print(v.T) # 印字 "[1 2 3]"
NumPy は配列操作関数が多い。http://docs.scipy.org/doc/numpy/reference/routines.array-manipulation.htmlを参照されたい。
ブロードキャスト#
ブロードキャストは算術的操作を行う際、NumPyが異なる shape の配列に強力な処 理機構を行うことを可能にする。
行列の各行に対して定数ベクトルを加える場合を以下に示す:
import numpy as np # 行列 x の各行に対してベクトル v を加え結果を y に格納 x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]]) v = np.array([1, 0, 1]) y = np.empty_like(x) # x と同じ shape を持つ空行列を生成 # 明示的繰り返しを用いて行列 x の各行にベクトル v の要素を加算 for i in range(4): y[i, :] = x[i, :] + v # y は以下のようになる # [[ 2 2 4] # [ 5 5 7] # [ 8 8 10] # [11 11 13]] print(y)
行列 x が巨大な場合Pythonの明示的なループは遅い。行列xの各行
にベクトル v を加えることはスタック領域に積まれたvのコピーと行
列 vv の和を構成することに等しい。以下の例のようになる。
import numpy as np # 行列 x の各要素にベクトル v を加える # 行列 y に結果を格納 x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]]) v = np.array([1, 0, 1]) vv = np.tile(v, (4, 1)) # v から4つのスタックを作成 print(vv) # 印字 "[[1 0 1] # [1 0 1] # [1 0 1] # [1 0 1]]" y = x + vv # x と vv の各要素を加える print(y) # 印字 "[[ 2 2 4 # [ 5 5 7] # [ 8 8 10] # [11 11 13]]"
NumPy のブロードキャストはyの多重コピーを作成することなく計算を
実行する。ブロードキャストを用いたバージョンを以下に示す:
import numpy as np # 行列 x の各行にベクトル v を加える # 結果を行列 y に格納する x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]]) v = np.array([1, 0, 1]) y = x + v # ブロードキャストを使って x の各行に v を加える print(y) # 印字 "[[ 2 2 4] # [ 5 5 7] # [ 8 8 10] # [11 11 13]]"
y = x + vの行は,xは(4,3)の次数を持ち,vは
(3,)の次数を持つことがブロードキャストによりy = x + vが計算され
る。もしvが次数(4,3)であるように作用する。各行はvの
コピーであり各要素の和が計算される。
2つの行列をブロードキャストする場合以下の規則に従う:
- もし二つの行列が同じ次数でなければ低次数の行列を拡張して等しくする。
- 二つの行列が,特定の次元のみ一致している場合,片方の配列の次元が1であっても、他の次元も同じサイズの次元にする。
- 二つの配列全ての次元に互換性があれば両者ともブロードキャストされる。
- ブロードキャスト後,各配列は両入力配列の次数が等しいとして振る舞う。
- 一方の配列のサイズが1であり他方の配列サイズが1より大きい場合,最初の 配列は次元を繰り返し複写して動作する
上記の意味が不明なら, http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html の http://wiki.scipy.org/EricsBroadcastingDoc 説明を読まれたい。
ブロードキャストをサポートする関数はユニバーサル関数として知られる。 ユニバーサル関数のリストは http://docs.scipy.org/doc/numpy/reference/ufuncs.html#available-ufuncs を参照のこと。
ブロードキャストの例を示す:
import numpy as np # ベクトルの外積を計算 v = np.array([1,2,3]) # v の次数 (3,) w = np.array([4,5]) # w の次数 (2,) # 外積を計算するため v の次数を列へと変形する # 次数 (3, 1) のベクトル; w に対してブロードキャストする # 外積の計算結果である次数 (3, 2) の行列を得る # [[ 4 5] # [ 8 10] # [12 15]] print(np.reshape(v, (3, 1)) * w) # 行列の各行にベクトルを加算する x = np.array([[1,2,3], [4,5,6]]) # x は次数 (2,3) であり v は (3,) である。v はブロードキャストされて (2,3) となり # x has shape (2, 3) and v has shape (3,) so they broadcast to (2, 3), # 以下の行列を得る: # [[2 4 6] # [5 7 9]] print(x + v) # 行列の各列にベクトルを加える # x の次数は (2, 3) であり,w の次数は (2,) である。 x を転置すれば # 次数は (3, 2) となり w はブロードキャストされ次数は (3, 2) となる。 # 結果は転置され次数 (2, 3) の行列となり以下の行列を得る: # [[ 5 6 7] # [ 9 10 11]] print((x.T + w).T) # 別解としては次数 (2, 1) の行ベクトルに対して次数を変換し, # その結果をブロードキャストして直接外積を計算する print(x + np.reshape(w, (2, 1))) # 行列の定数倍: # 行列 x の次数は (2, 3). Numpy はスカラを次数 () の配列として扱う: # スカラはブロードキャストされ次数 (2, 3) の行列となり以下の結果を得る # [[ 2 4 6] # [ 8 10 12]] print(x * 2)
ブロードキャストによりコードは簡潔になり,高速化する。 可能な限りブロードキャストを使うよう努めるべきである。
NumPy の文書#
ここでは NumPy に関して概説したが完全な記述には程遠い。NumPy のリファレンス http://docs.scipy.org/doc/numpy/reference/ には詳細が記されている。
SciPy#
NumPy は高性能な多次元配列を提供し,配列操作の基本道具を提供している。 SciPy は(http://docs.scipy.org/doc/scipy/reference/) NumPy で定義された配列と科学技術に有益な関数数多く用意している。
SciPy を理解するにはhttp://docs.scipy.org/doc/scipy/reference/index.html を観ることである。ここではSciPy の有益点いくつかに焦点をあてる。
画像操作#
SciPy は画像操作の基本関数を提供する。 例えば,ディスクから画像を読み込んで NumPy の配列に代入し, NumPy の配列を画像としてディスクに書き込み, 画像のサイズを変更する関数などである。 ここでは,これらの関数例を供覧する
from scipy.misc import imread, imsave, imresize # JPEG 画像を\NumPy 配列に読み込む img = imread('assets/cat.jpg') print(img.dtype, img.shape) # 印字 "uint8 (400, 248, 3)" # 各色チャンネルを異なるスカラ定数により色合いを変える。 # 画像は (400, 248, 3) の次数である。 # 次数 (3,) の配列 [1, 0.95, 0.9] を掛ける; # numpy のブロードキャストは赤チャンネルは変更せず, # 緑と青とをそれぞれ 0.95 倍,0.9 倍する img_tinted = img * [1, 0.95, 0.9] # 色合いを変更した画像を縦横 300 画素の画像に変換する img_tinted = imresize(img_tinted, (300, 300)) # 変更した画像をディスクに書き出す imsave('assets/cat_tinted.jpg', img_tinted)
Distance between points#
SciPy は点の集合間の距離を計算するための有益な関数が定義されている。
[scipy.spatial.distance.pdist]
関数は所与の集合に属する全点 間の距離を計算する:
import numpy as np from scipy.spatial.distance import pdist, squareform # 2次の行からなる以下の配列を定義する: # [[0 1] # [1 0] # [2 0]] x = np.array([[0, 1], [1, 0], [2, 0]]) print(x) # x の全ての行のユークリッド距離の計算 # d[i, j] は x[i, :] と x[j, :] との距離であり以下の行列となる # [[ 0. 1.41421356 2.23606798] # [ 1.41421356 0. 1. ] # [ 2.23606798 1. 0. ]] d = squareform(pdist(x, 'euclidean')) print(d)
詳細は http://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.pdist.html に記されている。
類似の関数 [scipy.spatial.distance.cdist] は 2 つの集合の 2 点間の全対の距
離を計算する。http://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.cdist.html を参照のこと。
Matplotlib#
Matplotlib は描画ライブラリである。 本節では Mycmdmatplotlib.pyplot モジュールを概説する。 MATLAB と同等のものである。
プロット#
Matplotlib の最重要関数は[plot] である。2 次元の描画が可能である。以下に例を示す:
import numpy as np import matplotlib.pyplot as plt # x, y 座標に正弦波を描く x = np.arange(0, 3 * np.pi, 0.1) y = np.sin(x) # matplotlib の plot 関数で描画 plt.plot(x, y) plt.show() # 画面に表示するために plt.show() を使う
上記のコードを実行することで以下の画像を得る。

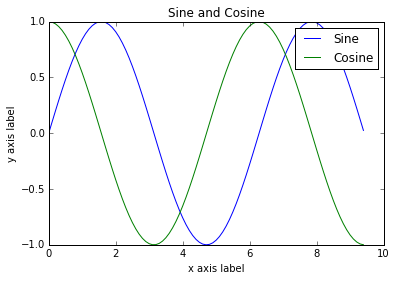
さらに手を加えると複数の線,タイトル,凡例,軸ラベルを描画可能である:
import numpy as np import matplotlib.pyplot as plt # x, y 座標上に正弦波と余弦波の曲線をプロットする x = np.arange(0, 3 * np.pi, 0.1) y_sin = np.sin(x) y_cos = np.cos(x) # matplotlib の plot を用いる plt.plot(x, y_sin) plt.plot(x, y_cos) plt.xlabel('x axis label') plt.ylabel('y axis label') plt.title('Sine and Cosine') plt.legend(['Sine', 'Cosine']) plt.show()
[plot]関数の詳細はhttp://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.plotから読むことができる。
サブプロット#
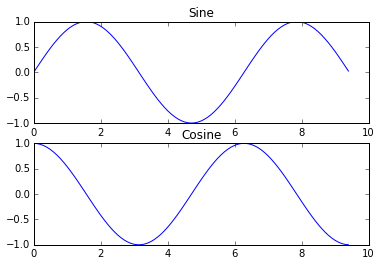
[subplot]関数を用れば同一図に別のプロットを入れることが可能である。
以下に例を示す:
import numpy as np import matplotlib.pyplot as plt # x, y 座標上で正弦波と余弦波をプロット x = np.arange(0, 3 * np.pi, 0.1) y_sin = np.sin(x) y_cos = np.cos(x) # 高さ2、幅1のサブプロット用格子を設定 # 最初のサブプロットをアクティブにする plt.subplot(2, 1, 1) # 最初のプロットを作成 plt.plot(x, y_sin) plt.title('Sine') # 2番目のサブプロットをアクティブにし,プロットを作成 plt.subplot(2, 1, 2) plt.plot(x, y_cos) plt.title('Cosine') # 図の画面表示 plt.show()
[subplot] 関数の詳細はhttp://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.subplotから読むことができる。
画像#
[imshow]関数を使て画像を表示することが可能である:
import numpy as np from scipy.misc import imread, imresize import matplotlib.pyplot as plt img = imread('assets/cat.jpg') img_tinted = img * [1, 0.95, 0.9] # 原画像の表示 plt.subplot(1, 2, 1) plt.imshow(img) # 色合いを変えた画像の表示 plt.subplot(1, 2, 2) plt.imshow(img_tinted) plt.show()

-
訳注:コード例Python3.4で動作するように書き換えた。2.7系は原典を参照されたい。 2.7 系と 3.4 系の相違についてはセバスチャン・ラシュカ(Sebastian Raschk) のブログ記事が参考になった(http://sebastianraschka.com/Articles/2014_python_2_3_key_diff.html)。邦訳も存在する(http://postd.cc/the-key-differences-between-python-2-7-x-and-python-3-x-with-examples/) ↩
-
訳注: 現行では[
python3]コマン ドで 3 系の Python が動作するパッケージが散見される(Anaconda<, Ubuntu, Homebrew, MacPorts, など) ↩ -
訳注:ドキュメントは URL 直下の数字が 2 か 3 かの違いにより,バージョンごとに文書が整備されているので 系の URL を逐次紹介することは避ける ↩
-
訳注: だからと言って日本語文字ファイル名問題が解決した訳ではない。もちろんそれはPythonの責任ではない ↩
-
訳注:関数の話をしていてクラス情報とは変であるが原文のままにした。おそらく関数制御とタイポしたのだろう ↩
-
Python, NumPy 用語で
rankとは配列の次元数を表す(1ならベクトル,2なら行列),shapeとは配列の各次元の要素数を指すタプル ↩