前回は、2標本の母平均の差の検定を行いました。 では、3標本ならどうなるでしょうか。
3標本の具体例として、大学生の生活に地域差があるかどうかを考えます。 全国すべてを調べるのは大変なので、東京23区、宮城県仙台市、および岩手県盛岡市の3つの地域を選んだとします。
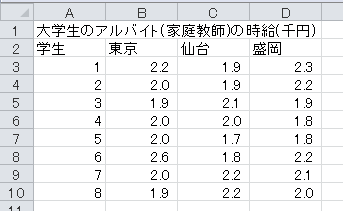
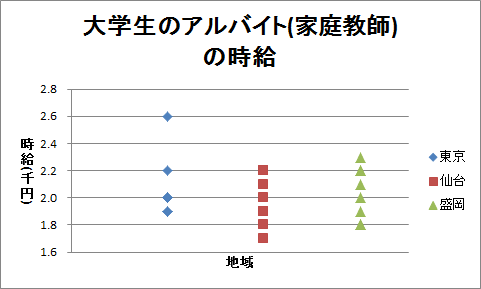
表「大学生のアルバイト(家庭教師)の時給」は、東京、仙台、および盛岡に住み、家庭教師のアルバイトをしている大学生それぞれ8人に、時給を聞いたものです。
東京の平均は2,075円、仙台の平均は1,975円、盛岡の平均は2,038円です。 地域差があるような気もしますが、全体的に散らばりが大きいので、地域差に見えるのが誤差の範囲内かもしれません。
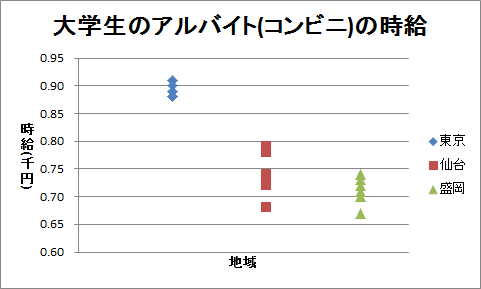
表「大学生のアルバイト(コンビニ)の時給」は、東京、仙台、および盛岡に住み、コンビニでアルバイトをしている大学生それぞれ8人に、時給を聞いたものです。
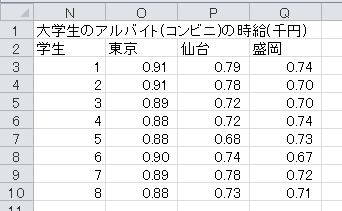
東京の平均は893円、仙台の平均は743円、盛岡の平均は714円です。 全体的に散らばりが小さいので、地域差がありそうです。
地域差を確かめるために、2標本の母平均の差の検定を、東京と仙台、仙台と盛岡、および盛岡と東京の3回行えば良いように思えますが、何度も検定を繰り返すと誤りが起こりやすくなることが知られています。 (後述の「多重比較」で詳しく説明します。)
3標本以上の場合は、 分散分析 ( analysis of variance , ANOVA )という手法を用います。 分散分析では、データに影響を与える要因を 因子 ( factor )と呼び、因子の項目を 水準 ( level )と呼びます。 上記の例なら、因子は地域、水準は東京、仙台、盛岡です。 因子が1種類なら 一元配置 ( one-way layout )と言い、2種類なら 二元配置 ( two-way layout )と言います。 上記の例は、因子は地域だけなので、一元配置です。 分散分析は、水準の違いと統計的誤差を比較して、本当に因子の効果があるかどうかを判断する分析方法です。 上記の例なら、東京、仙台、盛岡の違いと統計的誤差を比較して、本当に地域の効果があるかどうかを判断します。
分散分析の考え方を説明します。 簡単のため、3標本の場合のみ考えます。
標本 X の大きさを n 1 , 標本 Y の大きさを n 2 , 標本 Z の大きさを n 3 とします。 まず、各水準の平均を定義します。
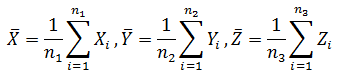
全体の平均 m も定義します。
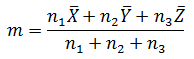
全体の変動 S は次のように定義されます。 ここで、 変動 とは 平方和 ( sum of squares , SS )とも呼ばれ、偏差(平均との差)の2乗の和です。
この全体の変動を、水準間の変動と水準内の変動に分解します。 水準間の変動 S 1 は、各水準の平均と全体の平均との差の2乗の和です。
水準内の変動 S 2 は、データとその水準の平均との差の2乗の和です。
実際、以下の等式が成り立ちます。
分解した変動から分散を求めます。 この分散は、偏差の2乗の平均なので、 平均平方 ( mean square , MS )と呼ばれることがあります。
水準間の変動 S 1 の自由度は3−1なので、水準間の分散 V 1 は分母を3−1にします。
水準内の変動 S 2 の自由度は n 1 + n 2 + n 3 −3なので、水準内の分散 V 2 は分母を n 1 + n 2 + n 3 −3にします。
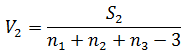
最後に分散比 F を定義します。
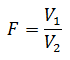
もし、 F が大きな値であれば、分子は分母より大きいことになり、水準間の差(水準の違い)は水準内の差(統計的誤差)より大きいことになります。 逆に、 F が小さな値であれば、分子は分母より小さいことになり、水準間の差(水準の違い)は水準内の差(統計的誤差)より小さいことになります。
この分散比 F は、自由度(3−1, n 1 + n 2 + n 3 −3)の F 分布に従うことが知られています。
分散分析では、帰無仮説は水準間の差(水準の違い)がないとし、対立仮説は水準間の差(水準の違い)があるとして、 F 検定が行われます。 もし、分散比 F が非常に大きくて、有意水準未満の確率でしか発生しない場合(すなわち有意である場合)、水準間の差(水準の違い)がないという帰無仮説は棄却され、水準間の差(水準の違い)があるという対立仮説が採択されるのです。
上記の家庭教師やコンビニの例なら、帰無仮説は時給に地域差がないとし、対立仮説は時給に地域差があるとします。 分散比 F が非常に大きくて有意であるならば、時給に地域差がないという帰無仮説は棄却され、時給に地域差があるという対立仮説が採択されます。
ここで、なぜ検定を繰り返してはいけないのかについて説明します。
有意水準5%で検定を行うことは、その検定は95%の確率で正しいということです。 もし3回検定を行うと、0.95×0.95×0.95=0.86なので、全体として86%の確率で正しいことになり、全体の有意水準が14%にもなってしまいます。 このため、本当は差がないのに、14%の確率で差があるという結論になってしまうのです。
人工的な例ですが、
とすると、分散分析では p 値が0.147となって差がないのですが、AとCで t 検定を行うと、 p 値が0.0486となって差があるという結論になってしまいます。
そうは言っても、分散分析で差があるという結論が出たら、次に、どれとどれに差があるかについて興味がわくでしょう。 これを調べるには、多重比較を行います。 多重比較 ( multiple comparison )とは、全体の有意水準が5%になるように、個別の有意水準を調節しながら検定を繰り返す方法です。 多重比較にはいくつか方法がありますが、 テューキーの方法 ( Tukey method )と呼ばれる多重比較がよく使われます。 「分析ツール」ではテューキーの方法はできないので、Rなど、他の統計解析ソフトを利用してください。
それでは、Excelを利用して、分散分析を行いましょう。 以下のExcelファイルをダウンロードしてください。
分散分析を行う前に、ドット・チャートを作成して、地域差があるかどうかを視覚的に把握します。 表「大学生のアルバイト(家庭教師)の時給」について、前回と同じように作成してください。 見たところ、地域差はなさそうです。
表「大学生のアルバイト(コンビニ)の時給」についても作成してください。 見たところ、地域差はありそうです。
「分析ツール」を利用すると、一元配置の分散分析が行えます。
リボンの「データ」をクリックし、「データ分析」をクリックします。 すると、「データ分析」ウィンドウが開くので、「分散分析: 一元配置」をクリックして、「OK」ボタンをクリックします。
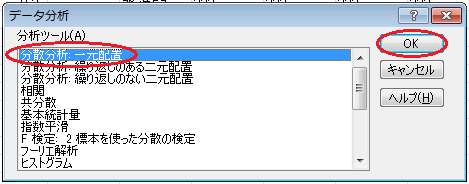
「入力範囲」にはデータの範囲($B$2:$D$10)を入力し、「データ方向」が「列」であることを確認し、「先頭行をラベルとして使用」チェックボックスをオンにし、「α」が「0.05」であることを確認し、「出力先」をクリックして、空いているセル(例えば$F$1)を入力します。
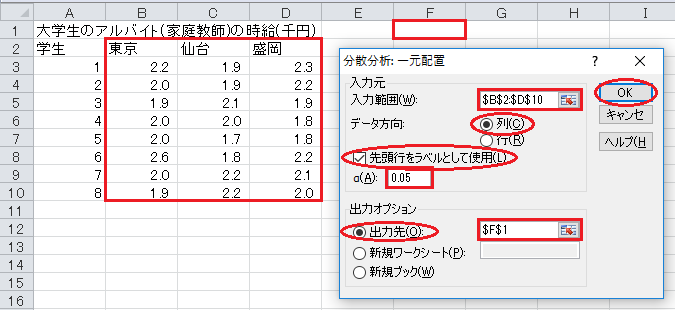
すると、分散分析の結果が出力されます。
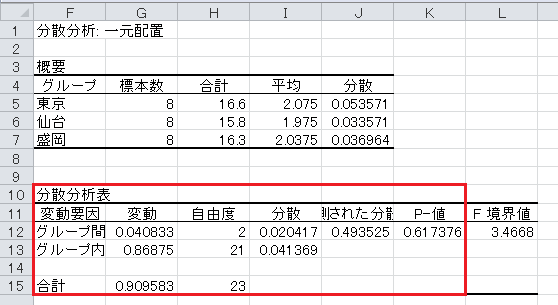
「分析ツール」の出力の読み方ですが、「グループ」を「水準」と読み替えてください。 「観測された分散比」が分散比 F です。
p 値が0.05以上なので、有意水準5%で有意ではなく、時給に地域差がないという帰無仮説は棄却されず、時給に地域差があるという対立仮説も採択されません。
分析の結果: 家庭教師のアルバイトの時給には地域差があるとは言えない。
コンビニのデータについても、同じように分散分析表が作成できます。 p 値の1.64E-11は1.64×10 -11 の意味で、小数で表すと0.0000000000164です。
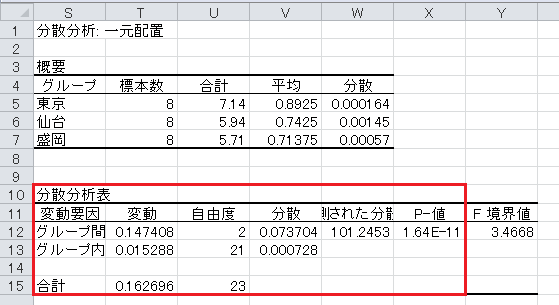
p 値が0.05未満なので、有意水準5%で有意であり、時給に地域差がないという帰無仮説は棄却され、時給に地域差があるという対立仮説が採択されます。
分析の結果: コンビニのアルバイトの時給には地域差があると言える。
以下のファイルをダウンロードしてください。
(1)表「大学生(下宿生)の1か月の食費」は、東京、仙台、および盛岡に住む大学生(下宿生)それぞれ8人に、1か月の食費を聞いたものです。 このデータのドット・チャートを作成してください。
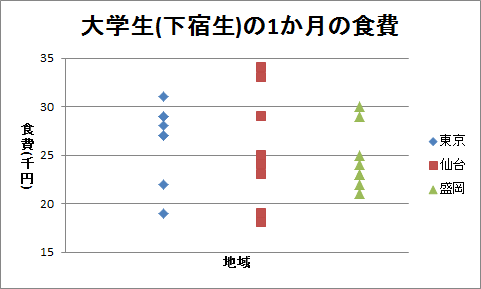
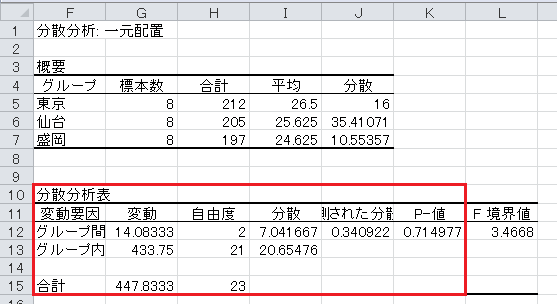
(2)食費のデータについて、帰無仮説は食費に地域差がないとし、対立仮説は食費に地域差があるとします。 有意水準5%で分散分析を行い、分析の結果を答えてください。
(3)表「大学生(下宿生)の1か月の家賃」は、東京、仙台、および盛岡に住む大学生(下宿生)それぞれ8人に、1か月の家賃を聞いたものです。 このデータのドット・チャートを作成してください。
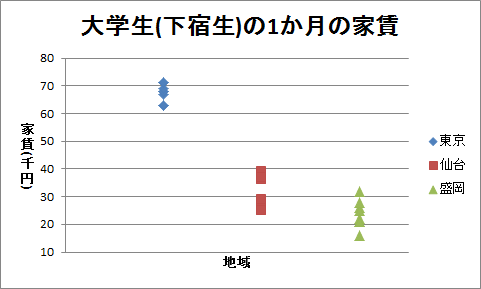
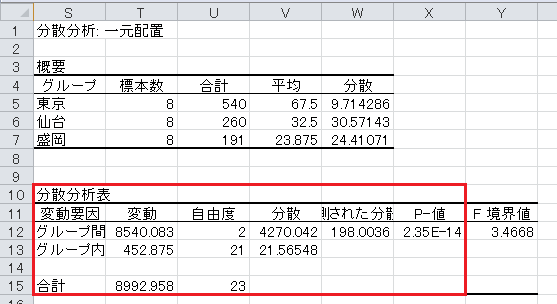
(4)家賃のデータについて、帰無仮説は家賃に地域差がないとし、対立仮説は家賃に地域差があるとします。 有意水準5%で分散分析を行い、分析の結果を答えてください。
今日の演習11の答案(Excelファイルと分析の結果)をメールで提出してください。 差出人は学内のメール・アドレス(学生番号@cis.twcu.ac.jp)とし、宛先はkonishi@cis.twcu.ac.jpとします。 メールの本文には、学生番号、氏名、科目名、授業日(12月7日)を明記してください。
分散分析の多重比較は、「分析ツール」ではできません。 情報処理センターで利用可能なソフトの中では、例えば、Rならできます。
R とは、フリーの統計解析ソフトで、研究・教育機関でよく利用されています。 ただし、
なので、初心者向けではありません。
RStudio とは、Rの各画面をウィンドウにまとめ、一部の操作をマウスで行えるようにしたものです。 今、Rを利用するなら、RStudioから操作したほうがよいです。
それでは、Finderのウィンドウを開き、「アプリケーション」をクリックし、「RStudio」をダブル・クリックしてください。 RStudioウィンドウが開き、その中のConsoleウィンドウの最後の行に、大なり記号( > )が表示されれば、コマンドが入力できます。

始めに、データを入力します。 RStudioで分散分析を行う場合、データを次の表の形に再構成します。
| area | T | T | T | T | T | T | T | T | S | S | S | S | S | S | S | S | M | M | M | M | M | M | M | M |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| payment | 0.91 | 0.91 | 0.89 | 0.88 | 0.88 | 0.90 | 0.89 | 0.88 | 0.79 | 0.78 | 0.72 | 0.72 | 0.68 | 0.74 | 0.78 | 0.73 | 0.74 | 0.70 | 0.70 | 0.74 | 0.73 | 0.67 | 0.72 | 0.71 |
RStudioは、日本語を使うと文字化けするので、地域をarea, 時給をpaymentにしています。 また、長い単語はグラフで省略されることがあるので、東京をT, 仙台をS, 盛岡をMにしています。
まず、地域(area)のデータを入力します。 次のコマンドをConsoleウィンドウにコピー・アンド・ペーストしてください。
area = c("T", "T", "T", "T", "T", "T", "T", "T", "S", "S", "S", "S", "S", "S", "S", "S", "M", "M", "M", "M", "M", "M", "M", "M")

ここで、 c はcollectionです。 続いて、時給(payment)のデータを入力します。 次のコマンドをConsoleウィンドウにコピー・アンド・ペーストしてください。
payment = c(0.91, 0.91, 0.89, 0.88, 0.88, 0.90, 0.89, 0.88, 0.79, 0.78, 0.72, 0.72, 0.68, 0.74, 0.78, 0.73, 0.74, 0.70, 0.70, 0.74, 0.73, 0.67, 0.72, 0.71)

これで、データの入力が終わります。
分散分析を行うには、次のコマンドをConsoleウィンドウにコピー・アンド・ペーストしてください。
summary(aov(payment ~ area))

ここで、 payment ~ area は時給(payment)を地域(area)で説明するという意味で、 aov は分散分析(Analysis Of Variance)という意味で、 summary は分かりやすく出力するという意味です。 Pr(>F) が p 値です。 「分析ツール」と同じ結果になっています。
Tukeyの方法を行うには、次のコマンドをConsoleウィンドウにコピー・アンド・ペーストしてください。
TukeyHSD(aov(payment ~ area))
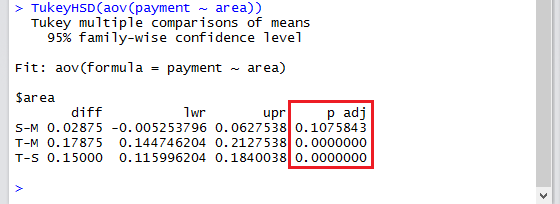
p adj が p 値です。 仙台-盛岡( S-M )に差があるとは言えませんが、東京-盛岡( T-M )には差があると言えて、東京-仙台( T-S )にも差があると言えます。 つまり、東京だけ違うということです。
Tukeyの方法をグラフで表すことができます。 次のコマンドをConsoleウィンドウにコピー・アンド・ペーストしてください。
plot(TukeyHSD(aov(payment ~ area)))
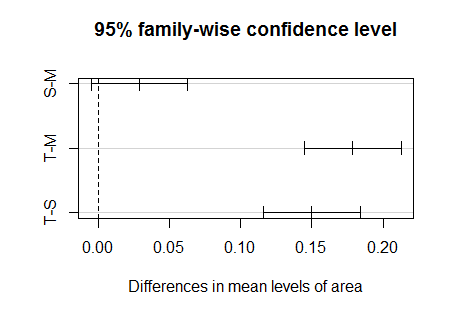
このグラフは、95%同時信頼区間と呼ばれるもので、95%信頼区間にゼロが含まれなければ、差があると言えます。 仙台-盛岡( S-M )に差があるとは言えませんが、東京-盛岡( T-M )には差があると言えて、東京-仙台( T-S )にも差があると言えます。 つまり、東京だけ違うということです。