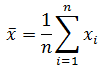
統計データが集まったら、まずは表やグラフにまとめて、全体的に理解するべきと説明しました。 次にやることは、統計データを代表するような値を見つけることです。
統計データの代表値として、最も重要なのが平均です。 平均 ( mean )は、データの合計をデータの個数で割ったものです。 つまり、データの個数が n で、データが x 1 , x 2 , ..., x n のとき、平均は、
と定義されます。 ( x は、エックス・バーと読みます。) シグマ記号を使わなければ、
です。
ここで、例として、ある中学校で、10人の生徒に対して国語の漢字テストと英語の単語テストが行われたとします。
| 生徒 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 漢字 | 7 | 6 | 8 | 7 | 8 | 6 | 7 | 7 | 7 | 7 |
| 単語 | 4 | 8 | 2 | 6 | 5 | 4 | 5 | 2 | 5 | 8 |
漢字テストと単語テストを比べると、どちらが難しかったでしょうか。 これは、両方の平均を計算して、比較すると分かります。 漢字テストの平均は、
です。 同じように単語テストの平均を計算すると、4.9点となります。 したがって、単語テストのほうが漢字テストより難しかったことが分かります。
統計データそのものが無く、度数分布表しか与えられない場合も考えられます。 このときは、データの合計の代わりに、「階級値×度数」の合計を計算します。 ここで、 階級値 ( midpoint )とは、階級を代表する値(普通は中間の値)です。
例えば、以下の度数分布表なら、
| 体重(kg) | 人数 |
|---|---|
| 50〜60 | 6 |
| 60〜70 | 3 |
| 70〜80 | 1 |
| 合計 | 10 |
平均体重は、
です。
平均といっても、必ずしも「合計して個数で割る」ものばかりではありません。 統計データによっては、掛け算をするもの( 幾何平均 ( geometric mean )
)や、逆数を合計するもの( 調和平均 ( harmonic mean )
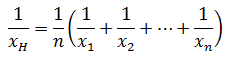
)もあります。
平均は最も重要な代表値ですが、その他の代表値もあります。
メディアン ( メジアン )( median )とは、 中央値 とも呼ばれ、データを小さい順に並べて中央にくる値のことです。 ただし、データの個数が偶数の場合、中央には2つの値がありますので、その2つの平均をとったものです。
例えば、データ
のメディアンは20です。 データ
のメディアンは (20+30)÷2=25 です。
モード ( mode )とは、 最頻値 とも呼ばれ、度数分布表において最も度数が多い階級の階級値のことです。
例えば、上記の体重の度数分布表では、モードは55kgになります。
上記の漢字テストと単語テストの得点をもう一度見てみましょう。 漢字テストはあまり得点差がないのに対して、単語テストは得点差が大きいような気がします。 この得点差、つまりデータの散らばり具合を表すのが、分散と標準偏差です。
分散 ( variance )は次のように定義されます。
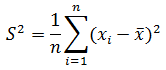
シグマ記号を使わなければ、
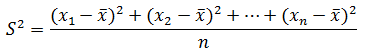
です。
分散は、要するに平均との差を集めているのです。 ここで、平均との差を2乗しているのは、負の数にしないためです。
漢字テストの平均は7.0点だったので、分散は、
です。 同じように単語テストの分散を計算すると、3.89となります。 これらの分散の単位は、点の2乗です。
分散にはもう一つの定義があります。
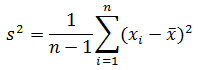
シグマ記号を使わなければ、
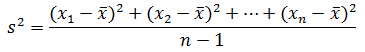
です。
分母が n の分散 S 2 は、データが全部(母集団)である場合に使います。 分母が n −1 の分散 s 2 は、データが一部(標本、サンプル)である場合に使います。
標準偏差 ( standard deviation )とは、分散の平方根です。 すなわち、
または
と定義されます。
分散は、データの単位が2乗になっているので、標準偏差は、平方根をとって単位を元に戻しているのです。
さて、漢字テストと単語テストを比べると、どちらが得点差が大きかったでしょうか。 これは、両方の標準偏差を計算して、比較すると分かります。 漢字テストの標準偏差は、
です。 同じように単語テストの標準偏差を計算すると、1.97点となります。 したがって、単語テストのほうが漢字テストより得点差が大きかったことが分かります。
分散と標準偏差の両方で、分母が n のものと分母が n −1 のものが定義されます。 データの個数が大きい場合は、 n で割っても n −1 で割っても大体同じ値になるので、どちらを使ってもかまいません。 データの個数が小さい場合は、値がずれてしまうので、どちらを使うか注意する必要があります。
散らばりの尺度としては、分散と標準偏差が重要ですが、他にもあります。
レンジ ( range )とは、 範囲 とも呼ばれ、
と定義されます。 レンジはデータの幅を表していますが、あまり使われません。
標準偏差の定義で、2乗する代わりに絶対値をとるもの( 平均偏差 ( mean deviation )
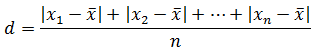
)もありますが、これもあまり使われません。
標準偏差は、データの散らばり具合の基準と考えられます。 個別のデータがどのくらい平均から離れているかを比べるとき、標準偏差の何倍離れているかを計算すれば、データの散らばり具合に関係のない比較ができます。 この計算をデータの 標準化 ( standardization )と言います。
データの標準化は
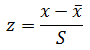
で計算します。
大学受験などでは、 偏差値 ( standard score )という尺度を利用します。 偏差値は、データの標準化をより身近な数値にしたものです。 具体的には、標準化 z に対して、偏差値 T は、
と定義されます。
それでは、Excelを利用して、平均、分散、標準偏差を計算しましょう。 同時に、標準化の表と偏差値の表も作成します。 次のExcelファイルをダウンロードしてください。
| student | kanji | word |
|---|---|---|
| 1 | 7 | 4 |
| 2 | 6 | 8 |
| 3 | 8 | 2 |
| ... | ... | ... |
| 10 | 7 | 8 |
まず、セルA13以下に「平均」、「分散」、「標準偏差」と入力します。
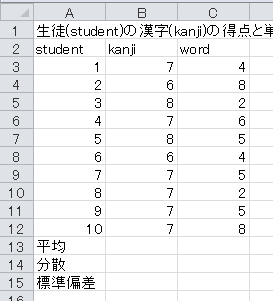
平均を計算するには、ExcelのAVERAGE関数を使うとできます。 この関数は、
という形式で、その範囲の平均を計算します。
それでは、セルB13に=AVERAGE(B3:B12)と入力してください。 漢字テストの平均が計算されます。 セルB13をC13にコピー・アンド・ペーストすると、単語テストの平均も計算されます。
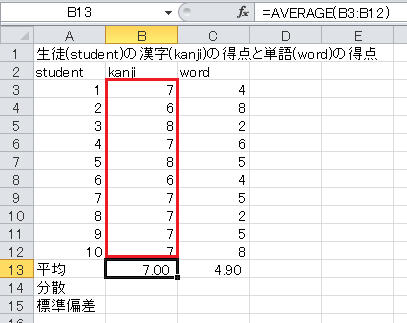
計算結果を小数点以下2桁の表示するには、セルの範囲をドラッグし、右クリックして「セルの書式設定」をクリックし、「表示形式」タブをクリックし、「分類」の「数値」をクリックし、「小数点以下の桁数」を2にします。
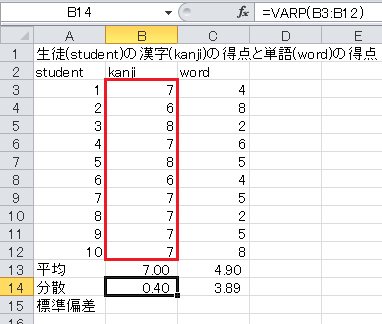
分散を計算するには、ExcelのVAR関数かVARP関数を使います。 (分散は英語でvarianceです。) これらの関数は
という形式で、その範囲の分散を計算します。 VAR関数は分母が n −1 のもの、VARP関数は分母が n のものです。 ここでは、分母が n のものを使います。
では、セルB14に=VARP(B3:B12)と入力してください。 漢字テストの分散が計算されます。 セルB14をC14にコピー・アンド・ペーストすると、単語テストの分散も計算されます。
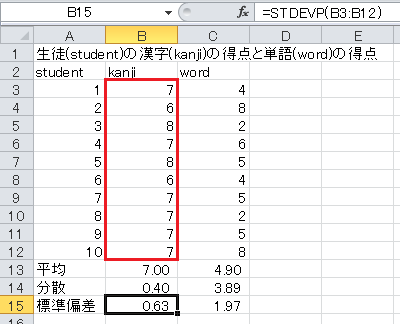
標準偏差を計算するには、定義通りなら分散の平方根を求めるのですが、Excelには標準偏差を直接計算するSTDEV関数とSTDEVP関数があります。 (標準偏差は英語でstandard deviationです。) これらの関数は
という形式で、その範囲の標準偏差を計算します。 STDEV関数は分母が n −1 のもの、STDEVP関数は分母が n のものです。 ここでは、分母が n のものを使います。
では、セルB15に=STDEVP(B3:B12)と入力してください。 漢字テストの標準偏差が計算されます。 セルB15をC15にコピー・アンド・ペーストすると、単語テストの標準偏差も計算されます。
平均と標準偏差が計算できたので、続いて標準化の表を作成します。 まず、セルE2から、「生徒」、「漢字」、「単語」、および生徒番号を入力します。
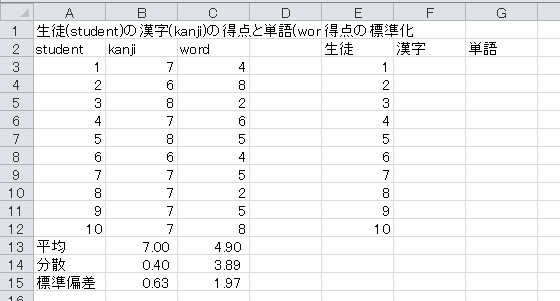
標準化の定義を日本語で書くと
なので、セルF3には
と入力します。 「セルの書式設定」で、小数点以下2桁の表示にしておきます。
そして、セルF3をF3からG12までにコピー・アンド・ペーストします。 これで、標準化の表が完成します。
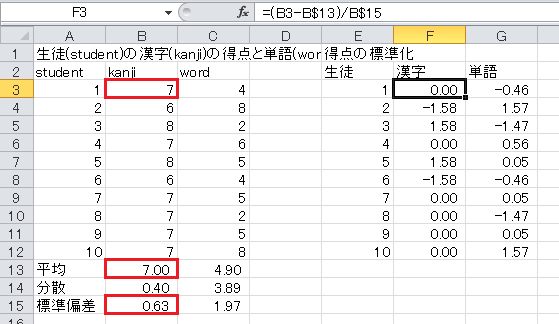
最後に、偏差値の表を作成します。 セルI2から、「生徒」、「漢字」、「単語」、および生徒番号を入力します。
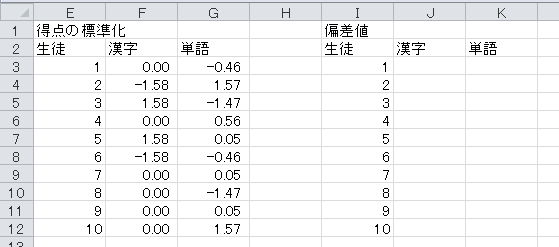
偏差値の定義を日本語で書くと
なので、セルJ3には
と入力します。 「セルの書式設定」で、小数点以下0桁の表示にしておきます。
そして、セルJ3をJ3からK12までにコピー・アンド・ペーストします。 これで、偏差値の表が完成します。
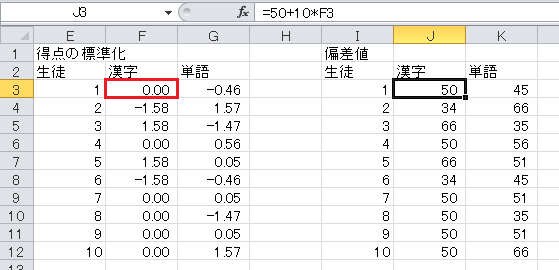
偏差値の表を見ると、例えば、生徒2は単語が漢字に比べて得意、生徒3は単語が漢字に比べて苦手などということが分かります。
Excelの分析ツールを利用すると、平均、分散、標準偏差など、基本的な統計量が一気に計算できます。 今日の演習では使いませんが、便利なので説明します。
まず、リボンの「データ」をクリックし、「分析」項目の「データ分析」をクリックします。 分析ツールのウィンドウが開いたら、「基本統計量」をクリックします。
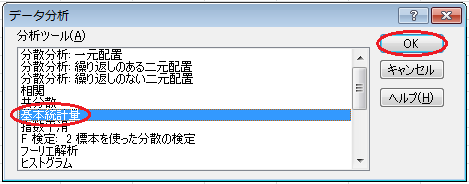
「基本統計量」ウィンドウの、「入力範囲」にはデータの範囲($B$2:$C$12)を入力し、「データ方向」の「列」をクリックし、「先頭行をラベルとして使用」のチェックを入れ、「出力先」をクリックし、出力先として余白(例えば$A$17)を入力し、「統計情報」のチェックを入れて、「OK」ボタンをクリックします。 すると、出力先に基本的な統計量が一覧表示されます。
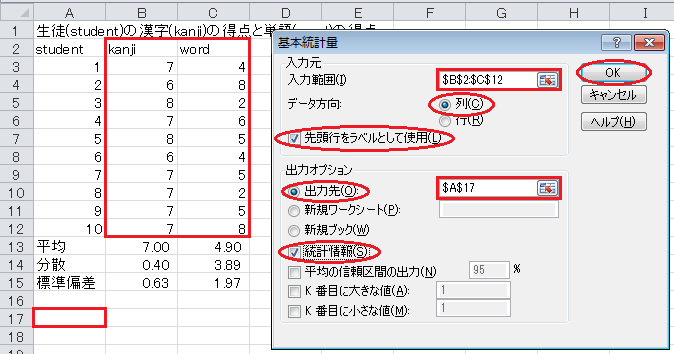
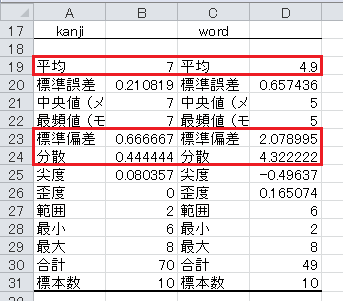
授業で説明していない統計量もありますが、気にしないでください。 ここで注目してほしいのは、分散と標準偏差が、VARP関数やSTDEVP関数の値より大きめになっていることです。 これは、分析ツールの基本統計量が、分母が n −1 のもの、すなわちVAR関数やSTDEV関数を使っているということです。
次に、「StatPlus」で平均と標準偏差を計算します。 「StatPlus」を起動し、メニューバーで「Statistics」→「Basic Statistics and Tables」→「Descriptive Statistics」とクリックします。 すると、「Descriptive Statistics」ウィンドウが開くので、「Variables」入力欄の右側のボタンをクリックし、Excelシートのデータの範囲(セルB2からC12まで)をドラッグします。 「Descriptive Statistics」ウィンドウの「Labels in first row」チェックボックスをオンにして、「OK」ボタンをクリックします。
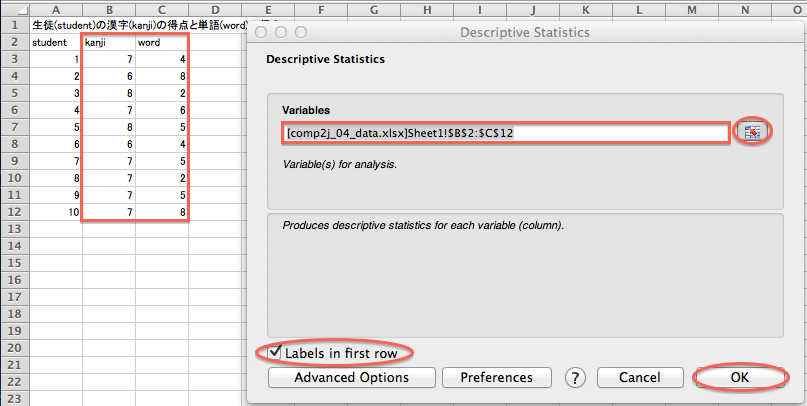
すると、新しくExcelのウィンドウが開き、この「Mean」、「Variance」、「Standard Deviation」という項目に、それぞれ平均、分散、標準偏差が表示されます。 「分析ツール」と同様に、分散と標準偏差は分母が n −1 のものです。
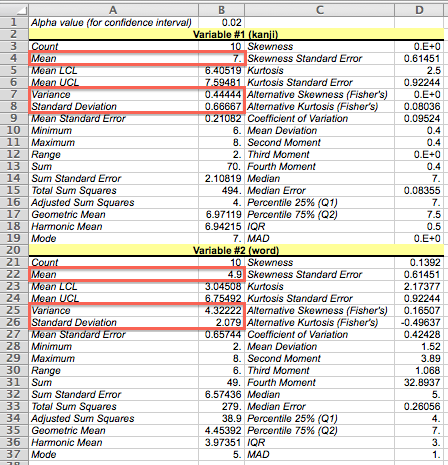
最後に、「Rコマンダー」で平均と標準偏差を計算します。 あらかじめ「Rコマンダー」を起動して、Excelシートのデータの範囲(セルB2からC12まで)をインポートしておいてください。 念のため、「Rコマンダー」ウィンドウの「データセットを表示」ボタンをクリックして、インポートしたデータを確認します。
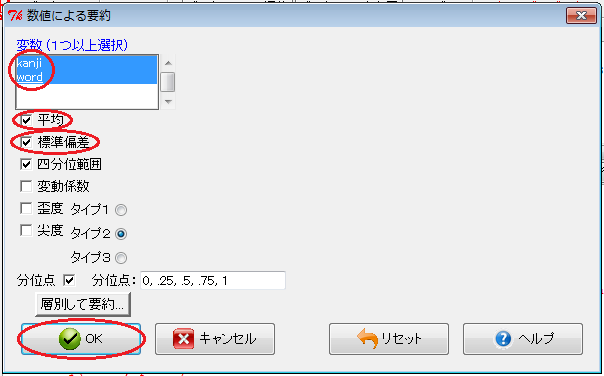
「Rコマンダー」ウィンドウで、「統計量」→「要約」→「数値による要約」とクリックします。 すると、「数値による要約」ウィンドウが開くので、「変数」欄の変数をクリックして選択し(shiftキーを押しながらクリックすると追加できます)、「平均」チェックボックスと「標準偏差」チェックボックスをオンにして、「OK」ボタンをクリックします。
すると、「Rコマンダー」ウィンドウの「出力ウィンドウ」欄の「mean」列に平均が表示され、「sd」列に標準偏差が表示されます。 「分析ツール」と同様に、標準偏差は分母が n −1 のものです。

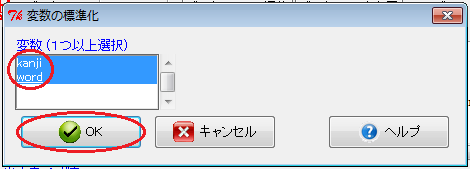
続いて、この標準偏差に基づいて、変数の標準化を行います。 「Rコマンダー」ウィンドウで「データ」→「アクティブデータセット内の変数の管理」→「変数の標準化」とクリックします。 すると、「変数の標準化」ウィンドウが開くので、標準化する変数をクリックします。 shiftキーを押しながらクリックすると、変数を追加できます。
「Rコマンダー」ウィンドウの「データセットを表示」ボタンをクリックすると、標準化された変数(「Z.」から始まる名前)が追加されたことが分かります。
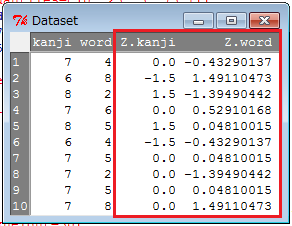
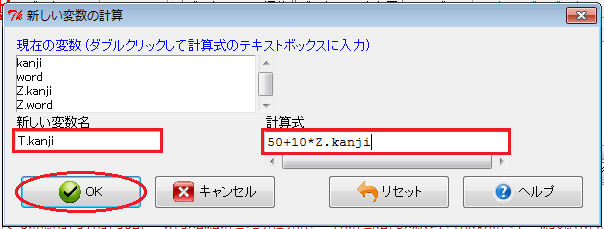
最後に、偏差値を計算します。 「Rコマンダー」ウィンドウで「データ」→「アクティブデータセット内の変数の管理」→「新しい変数の計算」とクリックします。 すると、「新しい変数の計算」ウィンドウが開くので、「新しい変数名」入力欄には例えば「T.kanji」、「計算式」入力欄には「50+10*Z.kanji」と入力します。
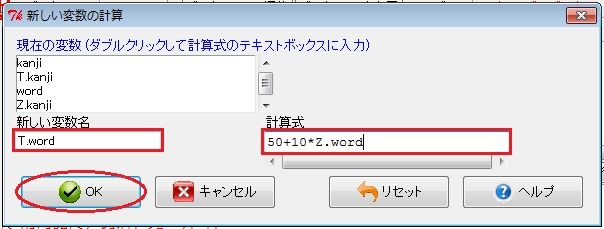
もう一度、「新しい変数の計算」ウィンドウを開いて、「新しい変数名」入力欄には例えば「T.word」、「計算式」入力欄には「50+10*Z.word」と入力します。
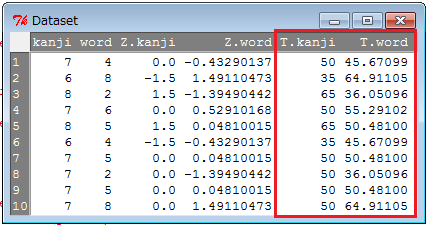
「Rコマンダー」ウィンドウの「データセットを表示」ボタンをクリックすると、偏差値が追加されたことが分かります。
このデータを保存するには、「Rコマンダー」ウィンドウで、「データ」→「アクティブデータセット」→「アクティブデータセットのエクスポート」とクリックします。 すると、「アクティブデータセットのエクスポート」ウィンドウが開くので、「行名をつける」チェックボックスをオフにし、「カンマ」ラジオ・ボタンをオンにして、「OK」ボタンをクリックします。
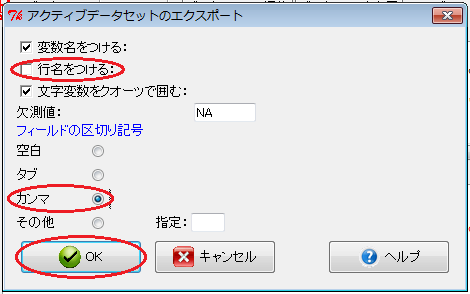
最後にファイル名を決めれば、CSV形式で保存されます。 このファイルはExcelで開けます。
ある中学校で、10人の生徒に対して、英語、数学、国語の3科目の小テストを実施したとします。 得点をまとめたExcelファイルをダウンロードしてください。
| student | English | mathematics | Japanese |
|---|---|---|---|
| 1 | 7 | 6 | 8 |
| 2 | 7 | 7 | 8 |
| 3 | 8 | 9 | 9 |
| ... | ... | ... | ... |
| 10 | 8 | 7 | 9 |
(1)3科目の平均と標準偏差を求めてください。 標準偏差は、分母が n のものにしてください。 数値の書式は、小数点以下2桁にしてください。
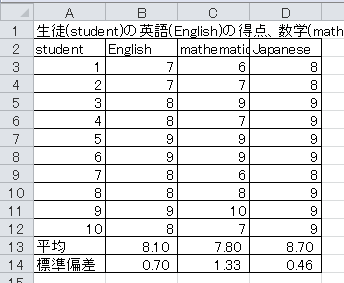
(2)3科目の得点を標準化して、表を作成してください。 数値の書式は、小数点以下2桁にしてください。
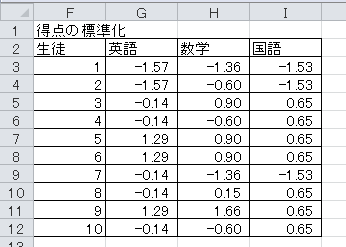
(3)3科目の偏差値を求め、表を作成してください。 数値の書式は、小数点以下0桁にしてください。
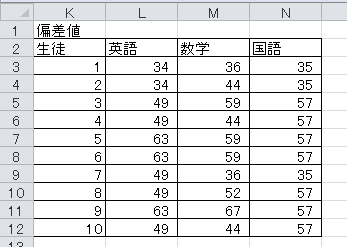
今日の演習4の答案(Excelファイル)をメールで提出してください。 差出人は学内のメール・アドレス(k12x1001@cis.twcu.ac.jpなど)とし、宛先はkonishi@cis.twcu.ac.jpとします。 メールの本文には、学生番号、氏名、科目名、授業日(10月22日)を明記してください。