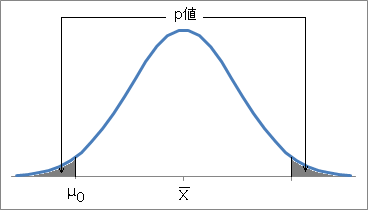
今、20歳以上の日本人男性の身長に関する、次の主張を考えます。
「標本平均は166.6cmかもしれないが、これには誤差があり、全国平均は166.0cmだと思う。」
つまり、母平均は166.0だという主張ですが、この主張は否定されるべきでしょうか。
前回の授業で、20歳以上の日本人男性の身長について、母平均の区間推定を行いました。 そのときの結果は、信頼度95%の信頼区間が[166.3, 166.9]でした。 主張の166.0はこの信頼区間の外側なので、この主張は95%の確率で否定されるべきというのが結論です。
ただ、主張を否定するためだけに信頼区間を計算するのは無駄です。 信頼区間の計算を思い出すと、信頼度95%の場合、標本の大きさ n , 標本平均 X , 標本標準偏差 s として、
でした。 つまり、信頼区間の下限と上限は、標本平均 X から標準誤差 s /√ n の1.960倍離れているということです。 したがって、この区間に主張の母平均μ 0 が入るかどうかは、主張の母平均が標本平均から標準誤差の何倍離れているかを
で計算し、 z と1.960を比較すれば分かるのです。
実際、 n =3022, X =166.6, s =7.2, μ 0 =166.0なので、
となり、4.58倍離れていることになります。 これは、1.960よりずっと大きいので、95%の確率で、母平均が166.0という主張は否定されるべきなのです。
今まで、信頼度95%にこだわってきましたが、これが99%ならどうかと聞かれると、両側5%点の1.960は使えなくなります。 特定の信頼度に依存しないために、逆に、主張の母平均が標本平均から標準誤差の4.58倍より大きく離れる確率を計算します。 このように計算された確率を、 p値 ( p-value )と呼びます。
この場合、 p 値は「4.58シグマ範囲」に入らない確率なので、Excelなどで計算すると0.000465%となります。 この p 値は5%よりずっと小さいので、95%の確率で、母平均が166.0という主張は否定されるべきです。
仮説検定 ( hypothesis testing )とは、母集団に関する仮説を立て、標本を調査することによって、仮説を否定したりしなかったりすることです。
仮説とは、例えば
のようなものです。
仮説を否定することを、仮説を 棄却 ( reject )すると言います。 仮説を肯定することを、仮説を 採択 ( accept )すると言います。
缶ジュースの例で言えば、A社のすべての缶ジュースを調べるわけにはいかないので、標本調査を行うことになります。 標本を調べても、平均がピッタリ350mlになる訳はなく、多少の誤差はあるはずです。 しかし、誤差と呼べないほどの差があれば、350mlであるという仮説は棄却して、缶ジュース製造機の故障を疑ったほうがよいでしょう。
仮説検定では、仮説と標本調査の差が誤差の範囲内か、それとも何か意味があるかを判断するために、確率を用います。 確率を例えば5%と設定し、5%未満の確率でしか発生しない差があれば、それは誤差ではなく、意味がある差だと結論付けます。 この5%を 有意水準 ( significance level )と言い、有意水準未満の確率でしか発生しない差を 有意 ( significant )な差と言います。 仮説と標本調査の差が有意なとき、短く「仮説は有意である」と言います。
仮説検定では、帰無仮説 H 0 と対立仮説 H 1 という2つの仮説を立てます。 帰無仮説 ( null hypothesis )は、棄却することを目的とした仮説です。 対立仮説 ( alternative hypothesis )は、採択することを目的とした仮説で、帰無仮説の反対の内容になります。
缶ジュースの例では、
帰無仮説 H 0 : 母平均は350mlである(μ=350)
対立仮説 H 1 : 母平均は350mlでない(μ≠350)
となります。
帰無仮説が有意である場合、すなわち有意水準未満の確率でしか発生しない場合、帰無仮説は棄却され、対立仮説が採択されます。 逆に、帰無仮説が有意でない場合、帰無仮説は棄却されず、対立仮説も採択されません。
仮説検定は、具体的には以下のいずれかの数値によって行われます。
信頼区間で検定を行う場合は、95%信頼区間に仮説の値(差があるか検定を行っているならゼロ)が入っていなければ、有意水準5%で有意なので帰無仮説は棄却され、対立仮説が採択されます。 逆に、95%信頼区間に仮説の値が入っていれば、有意水準5%で有意でないので帰無仮説は棄却されず、対立仮説も採択されません。
検定統計量(後述の z 統計量や t 統計量など)で検定を行う場合は、検定統計量(の絶対値)が両側5%点より大きいならば、有意水準5%で有意なので帰無仮説は棄却され、対立仮説が採択されます。 逆に、検定統計量(の絶対値)が両側5%点以下であれば、有意水準5%で有意でないので帰無仮説は棄却されず、対立仮説も採択されません。
p 値で検定を行う場合は、 p 値が0.05未満であれば、有意水準5%で有意なので帰無仮説は棄却され、対立仮説が採択されます。 逆に、 p 値が0.05以上であれば、有意水準5%で有意でないので帰無仮説は棄却されず、対立仮説も採択されません。
ここからは、特に母平均の仮説検定について考えます。 つまり、
帰無仮説 H 0 : 母平均はμ 0 である(μ=μ 0 )
対立仮説 H 1 : 母平均はμ 0 でない(μ≠μ 0 )
という仮説です。 缶ジュースの例も、このパターンです。
母平均の仮説検定は、標本の大きさが大きいときと小さいときに分かれます。 標本が大きいときは、正規分布に基づいて検定します。 標本が小さいときは、 t 分布に基づいて検定します。 この節では、正規分布の場合について説明し、 t 分布の場合については次節で説明します。
正規分布の両側5%点が1.960であることを思い出してください。 有意水準が5%の場合、標本の大きさ n , 標本平均 X , 標本標準偏差 s として、母平均が標本平均から標準誤差の何倍離れているかを
で計算します。 この値を、 z統計量 ( z-statistic )と呼びます。 そして、 z (の絶対値)が1.960より大きいならば、有意な差、すなわち5%未満の確率でしか発生しない差があるので、帰無仮説を棄却して対立仮説を採択します。 z (の絶対値)が1.960以下ならば、有意な差がないので、帰無仮説を棄却せず、対立仮説も採択しません。
缶ジュースの例では、母平均が350mlかどうかが問題で、350mlより大きくても350mlより小さくても区別しませんでした。 これに対して、より大きい(あるいはより小さい)かどうかが問題になる場合があります。 上記の例では、
これは、母比率πが0.5より大きいかどうかを問題にしています。 この場合、仮説は
帰無仮説 H 0 : 母比率は0.5である(π=0.5)
対立仮説 H 1 : 母比率は0.5より大きい(π>0.5)
となります。 また、正規分布の両側5%点1.960の代わりに、上側5%点1.645を使います。
このように、ある値かどうかが問題で、より大きくてもより小さくても区別しない検定を 両側検定 ( two-sided test )と呼び、より大きい(あるいはより小さい)かどうかを問題にする検定を 片側検定 ( one-sided test )と呼びます。
母平均の仮説検定で、標本が小さい場合は、正規分布の代わりに t 分布を使います。 t 分布に基づいた仮説検定を、 t検定 ( t-test )と呼びます。
有意水準が5%の場合、標本の大きさを n , 標本平均を X , 標本標準偏差を s として、母平均が標本平均から標準誤差の何倍離れているかを
で計算します。 この値を、 t統計量 ( t-statistic )と呼びます。 次に、自由度 n −1の t 分布の両側5%点を、Excelの関数TINV(0.05, n −1)で求めます。 最後に、 t (の絶対値)が両側5%点より大きいならば、有意な差、すなわち5%未満の確率でしか発生しない差があるので、帰無仮説を棄却して対立仮説を採択します。 t (の絶対値)が両側5%点以下ならば、有意な差がないので、帰無仮説を棄却せず、対立仮説も採択しません。
片側検定の場合は、両側5%点の代わりに、上側5%点を使います。 上側5%点は両側10%点なので、Excelの関数TINV(0.1, n −1)で求めます。
前回の授業では、母比率の区間推定を行いました。 母比率の仮説検定についても、同じように考えられます。 例えば、100人中60人が賛成する議題は、日本全国で過半数が賛成すると考えてよいか、などです。
簡単に言うと、仮説の母比率π 0 , 標本比率 p に対して、仮説の母平均をπ 0 , 標本平均を p , 標準偏差を√(π 0 ×(1−π 0 ))とすると、標本が大きな場合の方法で仮説検定ができます。 つまり、 z 統計量の計算式
の代わりに
を計算し、これと1.960(両側検定)または1.645(片側検定)を比較します。
なお、母比率の区間推定と母比率の仮説検定とでは、標準偏差の部分が異なっています。 これは、区間推定では母平均πが使えないので、母標準偏差√(π×(1−π))の代わりに標本標準偏差√( p ×(1− p ))にしたのです。
1種類のデータの仮説検定もそれなりに意味はありますが、応用上重要なのは、2種類のデータの仮説検定です。
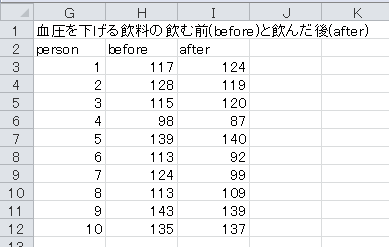
例えば、ある製薬会社が、血圧を下げると考えられる飲料を開発したとします。 本当に血圧が下がるのかを調べるには、次の2種類の方法があります。
(1) 協力者全員に一定期間その飲料を飲んでもらい、飲む前と飲んだ後の血圧を測定する。
(2) 協力者を2つのグループに分け、一定期間、一方にはその飲料を飲んでもらい、他方にはその飲料のニセモノ(偽薬、プラセボ)を飲んでもらう。 その後、両方のグループの血圧を測定する。
どちらも2種類のデータが得られますが、前者は同一人物の前後のデータです。 これを 対標本 (ついひょうほん)( paired sample )と呼びます。 それに対して、後者は他人同士のデータです。 これを 2標本 ( two sample )と呼びます。
今日は、対標本の検定を行います。 2標本の検定は次回行います。
実は、対標本は、本質的に1種類のデータです。 実際、前後のデータの差を計算し、差がゼロという帰無仮説のもとで検定を行えばよいのです。 しかし、応用上重要ということで、「分析ツール」、「StatPlus」、「Rコマンダー」のいずれでも、直接検定を行うことができます。
それでは、Excelを利用して、仮説検定を行いましょう。 以下のExcelファイルをダウンロードしてください。
最初のデータは、缶ジュースの容量についてです。 帰無仮説は母平均が350mlである、対立仮説は母平均が350mlでないとします。 有意水準5%で両側検定を行います。
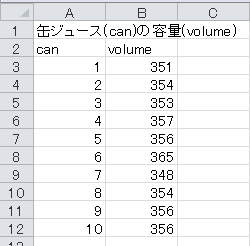
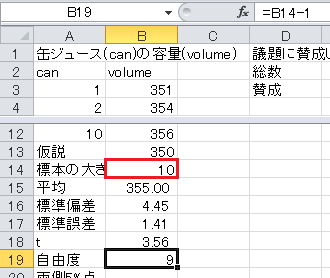
まず、セルA13から下に、「仮説」、「標本の大きさ」、「平均」、「標準偏差」、「標準誤差」、「t」、「自由度」、「両側5%点」と入力します。 仮説の350も入力します。
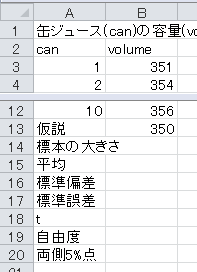
標本の大きさはExcelのCOUNT関数で求められます。 セルB14に=COUNT(B3:B12)と入力します。
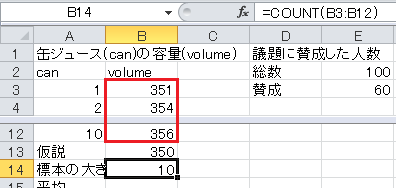
平均はExcelのAVERAGE関数で求められます。 セルB15に=AVERAGE(B3:B12)と入力します。
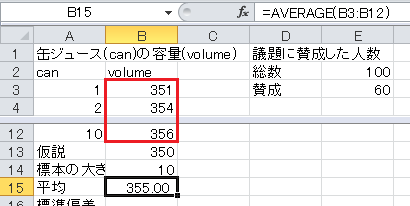
標準偏差はExcelのSTDEV関数で求められます。 セルB16に=STDEV(B3:B12)と入力します。
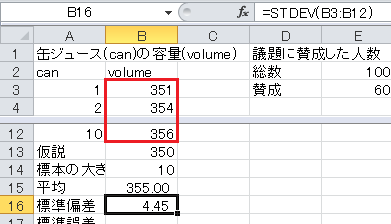
標準誤差=標準偏差/√標本の大きさ、なので、セルB17に=B16/SQRT(B14)と入力します。
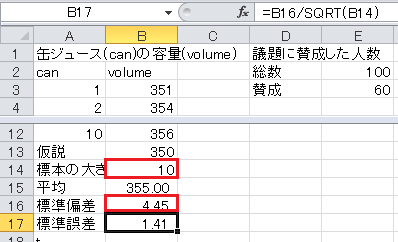
t =(平均−仮説)/標準誤差、なので、セルB18に=(B15-B13)/B17と入力します。
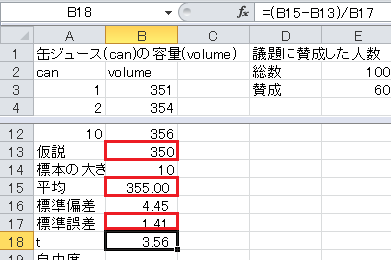
自由度=標本の大きさ−1, なので、セルB19に=B14-1と入力します。
t 分布の両側5%点はExcelのTINV関数で求められます。 関数の形式はTINV(確率, 自由度)なので、セルB20に=TINV(0.05,B19)と入力します。
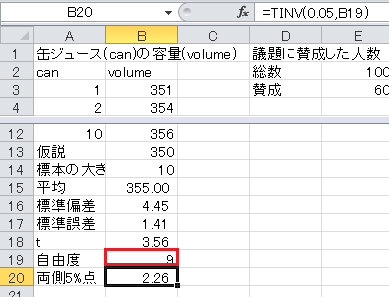
最後に t 統計量と両側5%点を比較します。
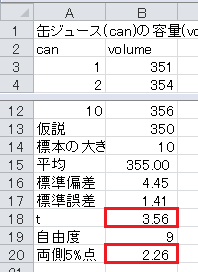
t 統計量が両側5%点より大きいので、有意水準5%で有意であり、母平均が350mlであるという帰無仮説は棄却され、母平均が350mlでないという対立仮説が採択されます。
検定の結果: 母平均が350mlでないと言える。
議題に賛成した人数の場合は、帰無仮説は母比率が50%, 対立仮説は母比率が過半数(50%を超える)とします。 有意水準5%で片側検定を行います。
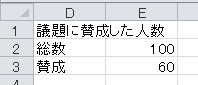
まず、セルD4から下に、「仮説」、「比率」、「標準偏差」、「標準誤差」、「z」、「上側5%点」と入力します。 仮説の0.5および正規分布の上側5%点の1.645も入力しておきます。
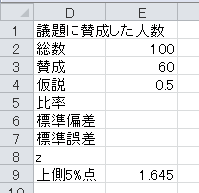
比率=賛成/総数、なので、セルE5に=E3/E2と入力します。
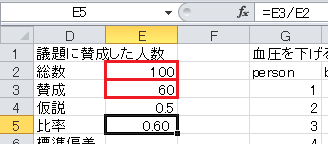
標準偏差=√(仮説×(1−仮説)), なので、セルE6に=SQRT(E4*(1-E4))と入力します。
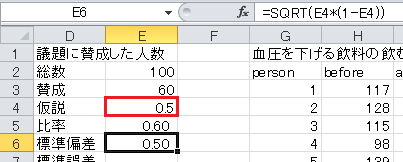
標準誤差=標準偏差/√総数、なので、セルE7に=E6/SQRT(E2)と入力します。
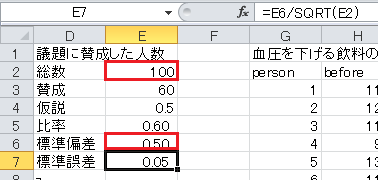
z =(比率−仮説)/標準誤差、なので、セルE8に=(E5-E4)/E7と入力します。
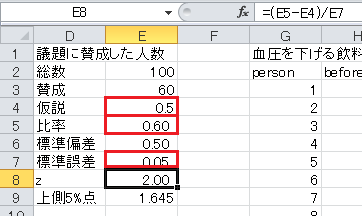
最後に z 統計量と上側5%点を比較します。
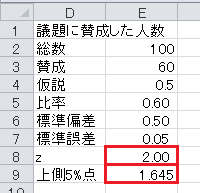
z 統計量が上側5%点より大きいので、有意水準5%で有意であり、母比率が50%という帰無仮説は棄却され、母比率が過半数という対立仮説が採択されます。
検定の結果: 過半数が賛成していると言える。
血圧を下げる飲料の場合、帰無仮説は血圧が変わらない、対立仮説は血圧が下がるです。 有意水準5%で片側検定を行います。
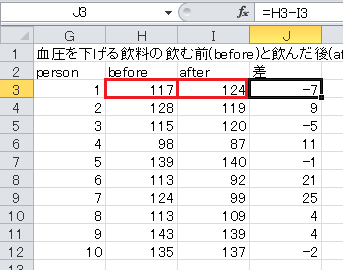
まず、血圧の差を求めます。 セルJ2に「差」と入力し、セルJ3に=H3-I3と入力し、これをセルJ12までコピー・アンド・ペーストします。
次に、セルI13から下に、「標本の大きさ」、「平均」、「標準偏差」、「標準誤差」、「t」、「自由度」、「上側5%点」と入力します。
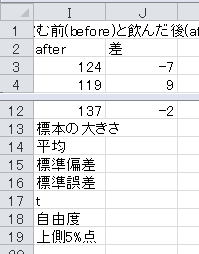
標本の大きさを求めます。
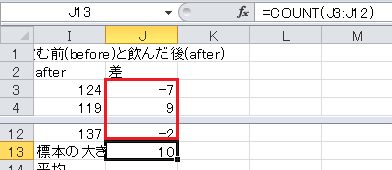
平均を求めます。
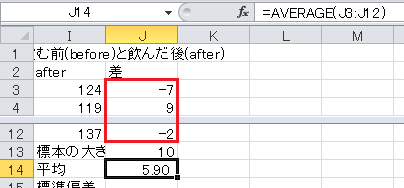
標準偏差を求めます。
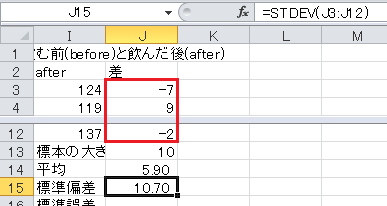
標準誤差=標準偏差/√標本の大きさ、です。
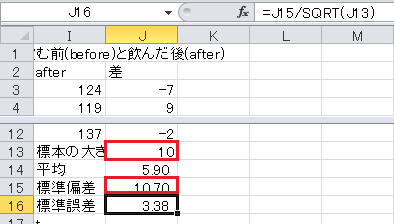
t =(平均−仮説)/標準誤差、ですが、血圧の差はゼロという仮説なので、平均/標準誤差、とします。
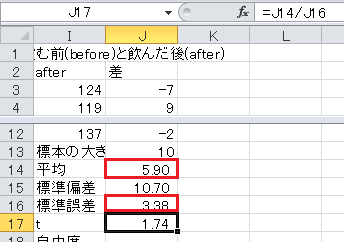
自由度=標本の大きさ−1, です。
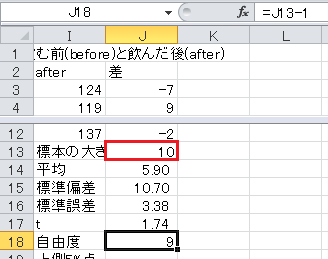
t 分布の上側5%点(=両側10%点)はExcelのTINV関数で求められます。 セルJ19に=TINV(0.1,J18)と入力します。
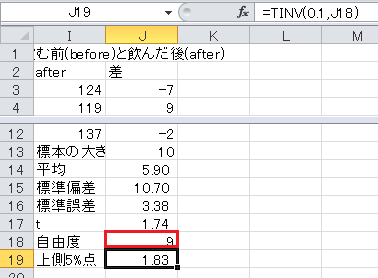
最後に t 統計量と上側5%点を比較します。
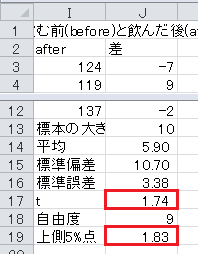
t 統計量が上側5%点以下なので、有意水準5%で有意ではなく、血圧が変わらないという帰無仮説は棄却されず、血圧が下がるという対立仮説も採択されません。
検定の結果: 血圧が下がるとは言えない。
ちなみに、対標本の場合、Excelの関数で直接 p 値を求めることができます。
TTEST(配列1,配列2,1,1)
で対標本の片側検定ができ、
TTEST(配列1,配列2,2,1)
で対標本の両側検定ができます。
セルI20に「p」と入力し、セルJ20に=TTEST(H3:H12,I3:I12,1,1)と入力すると、 p 値0.06が得られます。 これは0.05以上なので、有意水準5%で有意ではなく、血圧が変わらないという帰無仮説は棄却されず、血圧が下がるという対立仮説も採択されません。
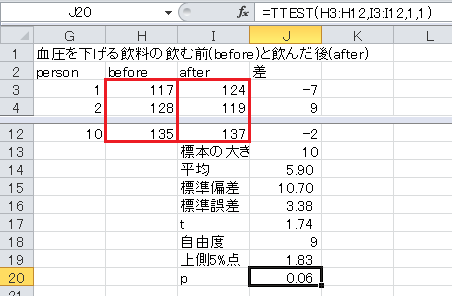
「分析ツール」を利用すると、対標本の仮説検定が行えます。 ここでは、血圧を下げる飲料について操作します。
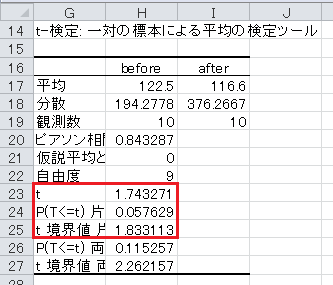
リボンの「データ」をクリックし、「分析」項目の「データ分析」をクリックします。 すると、「データ分析」ウィンドウが開くので、「t 検定: 一対の標本による平均の検定」をクリックして、「OK」ボタンをクリックします。
「変数 1 の入力範囲」に飲む前のデータ$H$2:$H$12を入力し、「変数 2 の入力範囲」に飲んだ後のデータ$I$2:$I$12を入力します。 「仮説平均との差異」は空欄のままにし、「ラベル」にチェックを入れ、「α」が0.05であることを確認します。 「出力オプション」の「出力先」をクリックし、空いているセル(例えば$G$14)を入力します。
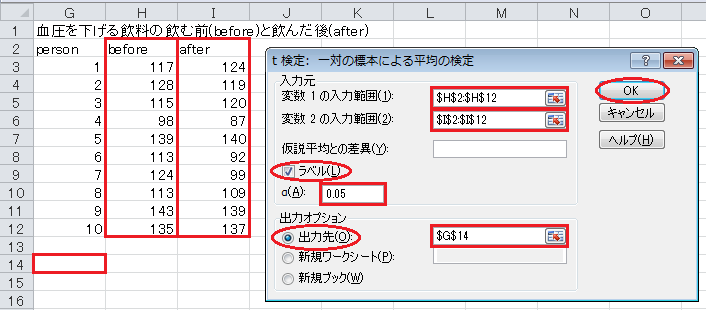
分析ツールの出力の読み方ですが、「t 境界値 片側」が上側5%点を表し、「t 境界値 両側」が両側5%点を表します。 「P(T<=t) 片側」が片側検定の p 値、「P(T<=t) 両側」が両側検定の p 値です。
最後に、 t 統計量と上側5%点を比較します。 t 統計量が上側5%点以下なので、有意水準5%で有意ではなく、血圧が変わらないという帰無仮説は棄却されず、血圧が下がるという対立仮説も採択されません。 片側検定の p 値も0.05以上なので、有意水準5%で有意ではなく、血圧が変わらないという帰無仮説は棄却されず、血圧が下がるという対立仮説も採択されません。
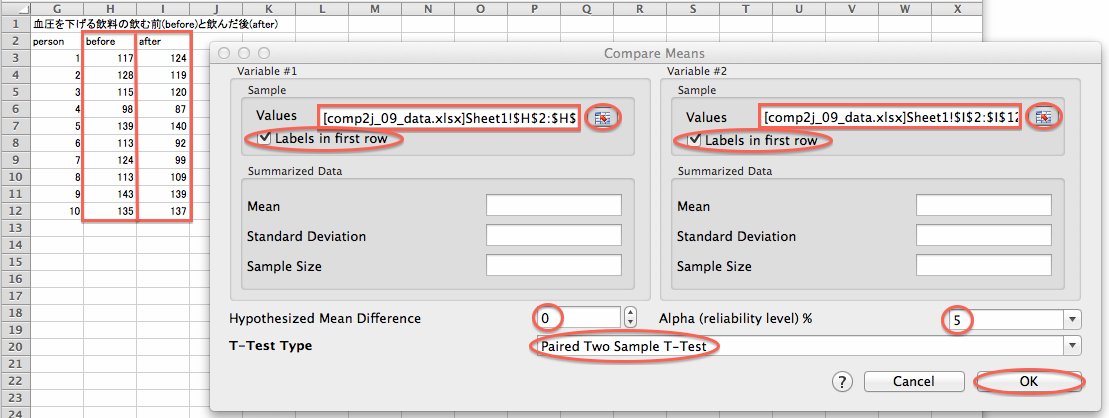
「StatPlus」を利用すると、対標本の仮説検定が行えます。 ここでは、血圧を下げる飲料について操作します。
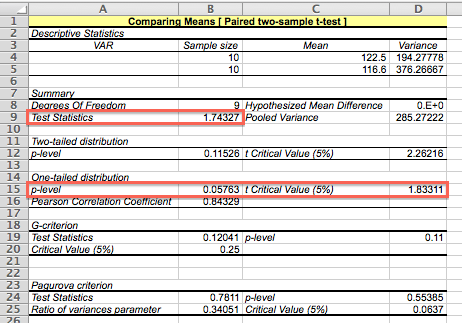
「StatPlus」を起動し、メニューバーで「Statistics」→「Basic Statistics and Tables」→「Comparing Means (T-test)」とクリックします。 すると、「Compare Means」ウィンドウが開くので、「Variable #1」項目の「Values」入力欄の右のボタンをクリックし、一方のデータの範囲(セルH2からH12まで)をドラッグして「Compare Means」ウィンドウをクリックし、「Labels in first row」チェックボックスをオンにします。 同様に、「Variable #2」項目の「Values」入力欄の右のボタンをクリックし、もう一方のデータの範囲(セルI2からI12まで)をドラッグして「Compare Means」ウィンドウをクリックし、「Labels in first row」チェックボックスをオンにします。 「Hypothesized Mean Difference」入力欄に「0」を入力し、「Alpha (reliability level) %」メニューを「5」にし、「T-Test Type」メニューを「Paired Two Sample T-Test」にして、「OK」ボタンをクリックします。
すると、新しくExcelのウィンドウが開き、表「Summary」の「Test Statistics」項目に t 統計量が表示されます。 表「Two-tailed distribution」が両側検定、表「One-tailed distribution」が片側検定で、それぞれ「p-level」項目が p 値、「t Critical Value (5%)」項目が5%点となります。
「Rコマンダー」を利用すると、1標本および対標本の仮説検定が行えます。 まず、缶ジュースについて操作します。 あらかじめ、「Rコマンダー」を起動して、データの範囲(セルB2からB12まで)をインポートしておきます。
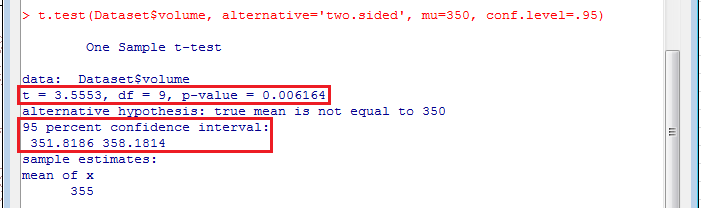
「Rコマンダー」ウィンドウで、「統計量」→「平均」→「1標本t検定」とクリックします。 すると、「1標本のt検定」ウィンドウが開くので、「変数」欄の変数名をクリックし、「対立仮説」項目で対立仮説(μ≠μ0)のラジオ・ボタンをオンにし、「帰無仮説」入力欄に仮説の母平均(350)を入力し、「信頼水準」入力欄に「.95」を入力し、「OK」ボタンをクリックします。
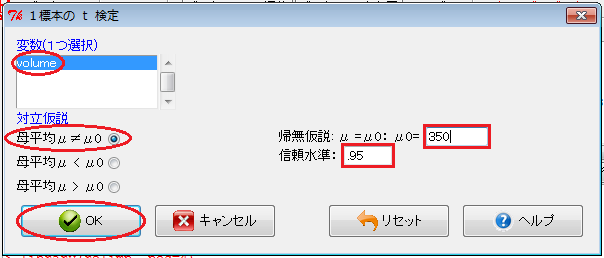
すると、「出力ウィンドウ」欄に、 t 統計量(t), 自由度(df), p 値(p-value)が表示されます。 また、95%信頼区間(95 percent confidence interval)も表示されます。 p 値を見ると、 p 値が0.05未満なので、有意水準5%で有意であり、母平均が350mlであるという帰無仮説は棄却され、母平均が350mlでないという対立仮説が採択されます。 信頼区間を見ると、仮説の母平均350が95%信頼区間の外側なので、有意水準5%で有意であり、母平均が350mlであるという帰無仮説は棄却され、母平均が350mlでないという対立仮説が採択されます。
次に、血圧を下げる飲料について操作します。 データの範囲(セルH2からI12まで)をインポートしておきます。
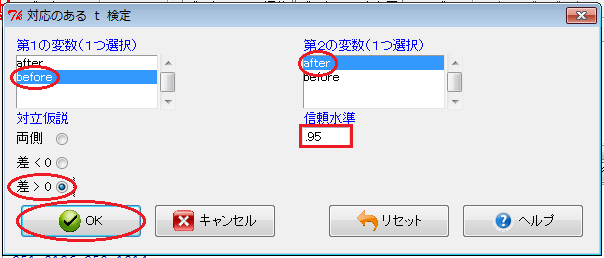
「Rコマンダー」ウィンドウで、「統計量」→「平均」→「対応のあるt検定」とクリックします。 すると、「対応のあるt検定」ウィンドウが開くので、「第1の変数」欄の変数名(before)をクリックし、「第2の変数」欄の変数名(after)をクリックし、「対立仮説」項目で対立仮説(差>0)のラジオ・ボタンをオンにし、「信頼水準」入力欄に「.95」を入力し、「OK」ボタンをクリックします。
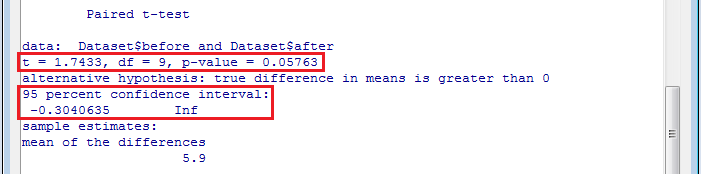
すると、「出力ウィンドウ」欄に、 t 統計量(t), 自由度(df), p 値(p-value)が表示されます。 また、95%信頼区間(95 percent confidence interval)も表示されます。 p 値を見ると、 p 値が0.05以上なので、有意水準5%で有意ではなく、血圧が変わらないという帰無仮説は棄却されず、血圧が下がるという対立仮説も採択されません。 信頼区間を見ると、95%信頼区間(Infは無限大です)にゼロが入っているので、有意水準5%で有意ではなく、血圧が変わらないという帰無仮説は棄却されず、血圧が下がるという対立仮説も採択されません。
以下のファイルをダウンロードしてください。
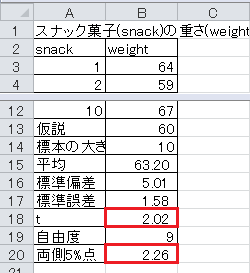
(1)表「スナック菓子の重さ」は、ある食品メーカーのスナック菓子の重さが平均60gかどうかを標本調査したものです。 帰無仮説は母平均が60gであるとし、対立仮説は母平均が60gでないとします。 有意水準5%で両側検定を行い、検定の結果を答えてください。
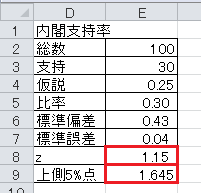
(2)表「内閣支持率」は、ランダムに選んだ100名に内閣を支持するかどうかを聞いたものです。 この調査から、内閣支持率は25%を超えていると言えるかどうかを考えます。 帰無仮説は母比率が0.25であるとし、対立仮説は母比率が0.25を超えるとします。 有意水準5%で片側検定を行い、検定の結果を答えてください。
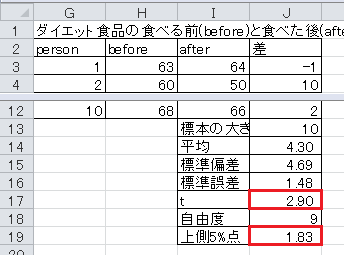
(3)表「ダイエット食品の食べる前と食べた後」は、あるダイエット食品を1か月間食べ続けてもらい、食べる前と食べた後の体重を測定したものです。 この調査から、このダイエット食品は効果があるかどうかを考えます。 帰無仮説は体重が変わらないとし、対立仮説は体重が減ったとします。 有意水準5%で片側検定を行い、検定の結果を答えてください。
今日の演習9の答案(Excelファイルと検定の結果)をメールで提出してください。 差出人は学内のメール・アドレス(k12x1001@cis.twcu.ac.jpなど)とし、宛先はkonishi@cis.twcu.ac.jpとします。 メールの本文には、学生番号、氏名、科目名、授業日(12月4日)を明記してください。