[->“ú–{Śę ]
It is unscalable the extention and amount of positive effects of information technologies on community of persons with visual impairments. One reason of it is that information technologies include braille in seamless fashion (Recently Unicode registered braille characters as its part!).
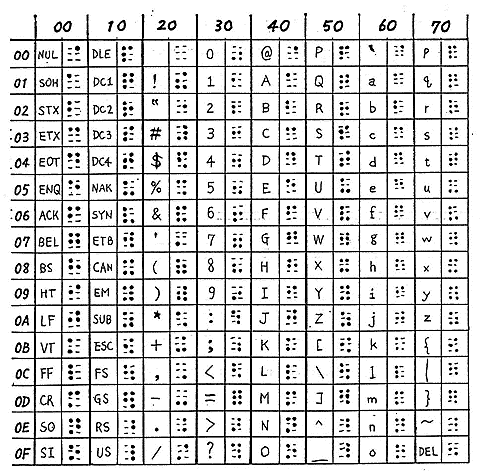
The following shown is a computer braille code table. What is wonderful about this code is that it gives us the way that all braille characters could be expressed by ASCII characters, and all ASCII characters could be expressed by braille code as well (quite similar to that of ordinary terminal control).
As shown, a braille character having only 6 dots, or 6 bits, inevitably cannot express all 7 bit ASCII characters. The same braille character corresponds to both upper and lower case characters. Control characters should be input with modifier keys.
The computer braille is different from the ordinary braille notation in some ways. For instance, all numbers are allocated single characters each, which is different from ordinary braille. In ordinary braille, number sign (a hash character) is required to precedes A, B, C to denote 1, 2, 3. Number one is #A in braille notation. In other words, there is not number characters in ordinary braille notation. In computer braille, on the contrary, there are stand-alone number characters, after Nemeth braille code which is used in science and math education in USA.
The computer braille code shown below is somtimes called NABCC (North American Braille Computer Code).