文字列などのデータを数種類の記号の列に変換することを、 符号化 ( encoding ) と言います。 符号化されたデータを元に戻すことを、 復号 ( decoding ) と言います。
コンピュータが使われるまでは、符号化は数字の列に変換することが多かったのですが、コンピュータでデータを処理する現在は、普通はビットの列に変換します。
符号化は、データを保存するときに行われます。 つまり、データは符号化されてビット列になり、各ビットがハード・ディスクの磁気状態などとして記録されます。 また、データを転送するときにも符号化が行われます。 各ビットは、銅線の電気信号などとして通信されます。
今回は、文字列の符号化について考えます。
文字の符号化で国際標準となっているのが、 ASCII符号 ( ASCII code ) です。 以下は、ASCII符号の一部です。
| 文字 | 符号 | 文字 | 符号 | 文字 | 符号 |
|---|---|---|---|---|---|
| @ | 0100 0000 |
` | 0110 0000 |
||
| ! | 0010 0001 |
A | 0100 0001 |
a | 0110 0001 |
| " | 0010 0010 |
B | 0100 0010 |
b | 0110 0010 |
| # | 0010 0011 |
C | 0100 0011 |
c | 0110 0011 |
| $ | 0010 0100 |
D | 0100 0100 |
d | 0110 0100 |
| % | 0010 0101 |
E | 0100 0101 |
e | 0110 0101 |
| & | 0010 0110 |
F | 0100 0110 |
f | 0110 0110 |
| ' | 0010 0111 |
G | 0100 0111 |
g | 0110 0111 |
| ( | 0010 1000 |
H | 0100 1000 |
h | 0110 1000 |
| ) | 0010 1001 |
I | 0100 1001 |
i | 0110 1001 |
| * | 0010 1010 |
J | 0100 1010 |
j | 0110 1010 |
| + | 0010 1011 |
K | 0100 1011 |
k | 0110 1011 |
| , | 0010 1100 |
L | 0100 1100 |
l | 0110 1100 |
| - | 0010 1101 |
M | 0100 1101 |
m | 0110 1101 |
| . | 0010 1110 |
N | 0100 1110 |
n | 0110 1110 |
| / | 0010 1111 |
O | 0100 1111 |
o | 0110 1111 |
| 0 | 0011 0000 |
P | 0101 0000 |
p | 0111 0000 |
| 1 | 0011 0001 |
Q | 0101 0001 |
q | 0111 0001 |
| 2 | 0011 0010 |
R | 0101 0010 |
r | 0111 0010 |
| 3 | 0011 0011 |
S | 0101 0011 |
s | 0111 0011 |
| 4 | 0011 0100 |
T | 0101 0100 |
t | 0111 0100 |
| 5 | 0011 0101 |
U | 0101 0101 |
u | 0111 0101 |
| 6 | 0011 0110 |
V | 0101 0110 |
v | 0111 0110 |
| 7 | 0011 0111 |
W | 0101 0111 |
w | 0111 0111 |
| 8 | 0011 1000 |
X | 0101 1000 |
x | 0111 1000 |
| 9 | 0011 1001 |
Y | 0101 1001 |
y | 0111 1001 |
| : | 0011 1010 |
Z | 0101 1010 |
z | 0111 1010 |
| ; | 0011 1011 |
[ | 0101 1011 |
{ | 0111 1011 |
| < | 0011 1100 |
\ | 0101 1100 |
| | 0111 1100 |
| = | 0011 1101 |
] | 0101 1101 |
} | 0111 1101 |
| > | 0011 1110 |
^ | 0101 1110 |
~ | 0111 1110 |
| ? | 0011 1111 |
_ | 0101 1111 |
符号化で重要なことは、復号して正確に元に戻ることです。 このことを、 一意的に復号化可能 ( uniquely decodable ) と言います。 一意的に復号化可能であるためには、異なるデータは異なるビット列に符号化されなければなりません。
ASCII符号は一意的に復号化可能です。 なぜなら、ビット列を8ビットごとに区切ればよいからです。
例えば、文字列"ABC"は、
010000010100001001000011
と24ビットに符号化されます。 復号するときは、これを
01000001 01000010 01000011
と8ビットごとに区切り、それぞれを復号すれば、文字列"ABC"に戻ります。
符号化を工夫することによってビット列を短くすることを、 データ圧縮 ( data compression ) と言います。 データによっては工夫の余地がないものもありますが、多くのデータは何らかの符号化によって圧縮可能です。
データ圧縮には多くのメリットがあります。 ハード・ディスクにより多くのデータが記録できますし、データを通信するときの時間や費用が節約できます。
今回は文字列のデータ圧縮を考えるわけですが、まず注目すべきなのは、文字列に現れる文字の種類です。 文字の種類が少なければ少ないほど、1文字をより短いビット列に符号化できます。 具体的には、次の表の通りです。
| ビット長 | 文字数 |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 8 |
| 4 | 16 |
| 5 | 32 |
| 6 | 64 |
| 7 | 128 |
例として、文字列"AAAAAAAABBBBBBCCCCDD"を圧縮します。
ASCIIで符号化しますと、160ビットになります。
一方、文字は"A", "B", "C", "D"の4種類しかありませんので、"A"を
00
, "B"を
01
, "C"を
10
, "D"を
11
と、1文字2ビットに符号化しますと、
00 00 00 00 00 00 00 00 01 01 01 01 01 01 10 10 10 10 11 11
と、40ビットに符号化されます。
なお、すべての文字を同じ長さのビット列に符号化する符号のことを、 固定長符号 ( fixed-length code ) と呼びます。 固定長符号は一意的に復号化可能です。
ランレングス符号 ( run-length code ) は、同じ文字が連続して現れるときに効果的な圧縮法です。 これは、上記の文字列"AAAAAAAABBBBBBCCCCDD"なら、これをいったん"8A6B4C2D"に変換してから符号化するものです。
変換結果を固定長符号で符号化しますと、文字の種類は元の4種類と数字の10種類ですので、次のように1文字4ビットに符号化できます。
| 文字 | 符号 |
|---|---|
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| 3 | 0011 |
| 4 | 0100 |
| 5 | 0101 |
| 6 | 0110 |
| 7 | 0111 |
| 8 | 1000 |
| 9 | 1001 |
| A | 1010 |
| B | 1011 |
| C | 1100 |
| D | 1101 |
| E | 1110 |
| F | 1111 |
したがって、
1000 1010 0110 1011 0100 1100 0010 1101
と、32ビットに符号化されます。 単純な固定長符号では40ビットでしたので、ランレングス符号によって、より圧縮されたことが分かります。
ランレングス符号では、元の文字列に数字が現れないようにする必要があります。 また、連続しない文字を"1E"のようにしますと、逆に長くなりますので、これは"E"のままにします。
上記の文字列"AAAAAAAABBBBBBCCCCDD"を並び替えた文字列"ABCACBABDAABCACBABDA"の圧縮を考えます。 ランレングス符号では圧縮できませんので、他の符号化を考えます。
方針は、よく現れる文字は短いビット列で符号化し、あまり現れない文字は長いビット列で符号化することです。 このような、文字によってビット列の長さを変える符号を、 可変長符号 ( variable-length code ) と呼びます。
可変長符号は、一般的には一意的に復号化可能ではありません。
例えば、"A"を
0
, "B"を
01
, "C"を
10
に符号化しますと、
010
は"AC"にも"BA"にも復号されます。
一意的でないのは、"A"の符号
0
が"B"の符号
01
の語頭だからです。
ここで、
語頭
(
prefix
)
とは、先頭からの部分列のことです。
符号化は、どの文字の符号も他の文字の符号の語頭でないという、
語頭条件
(
prefix condition
)
を満たせば、一意的に復号化可能です。
可変長符号では、 ハフマン符号 ( Huffman code ) が、一意的に復号化可能で、かつ最もよい圧縮法です。 以下にその作り方を示します。
まず、文字列における文字の出現頻度を調べます。 上記の文字列では、"A" = 8, "B" = 6, "C" = 4, "D" = 2 です。 次に、出現頻度の低いほうから2つを「合併」します。 なお、最も低いものが3つ以上ある場合は、その中から任意の2つを選びます。 また、最も低いものが1つあり、次に低いものが2つ以上ある場合は、最も低いものと、次に低いものの中から任意の1つを選びます。 この場合は、"C" = 4 と "D" = 2 を合併して、"C" + "D" = 6 とします。 この合併を、1つになるまで繰り返します。 この場合は、
| "A" = 8, "B" = 6, "C" = 4, "D" = 2 | → | "A" = 8, "B" = 6, "C" + "D" = 6 |
| → | "A" = 8, "B" + ("C" + "D") = 12 | |
| → | "A" + ("B" + ("C" + "D")) = 20 |
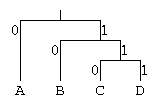
です。 そして、合併の過程をトーナメント表にします。 この場合は、次のようになります。
最後に、トーナメント表の上からたどり、左側を
0
に、右側を
1
に対応させます。
この場合は、"A"は
0
, "B"は
10
, "C"は
110
, "D"は
111
です。
以上の手続きによって、並び替える前の文字列"AAAAAAAABBBBBBCCCCDD"は
0 0 0 0 0 0 0 0 10 10 10 10 10 10 110 110 110 110 111 111
と、38ビットに符号化されます。 もちろん、並び替えた後の文字列も、38ビットに符号化されます。
以上の結果をまとめますと、次のようになります。
| 文字列 | 固定長符号 | ランレングス符号 | ハフマン符号 |
|---|---|---|---|
| "AAAAAAAABBBBBBCCCCDD" | 40ビット | 32ビット | 38ビット |
| "ABCACBABDAABCACBABDA" | 40ビット | 80ビット | 38ビット |
ランレングス符号は特別な場合でしか圧縮できませんが、ハフマン符号は大抵の場合で圧縮できることが分かります。
例題1. 文字列"AAABBBCCDD"を固定長符号、ランレングス符号、およびハフマン符号で符号化し、符号の長さを比較してください。
解答例1. 固定長符号については、文字が4種類なので1文字2ビットで符号化して、符号の長さは20ビットになる。 ランレングス符号については、いったん"3A3B2C2D"に変換する。 文字と数字で14種類になるので、1文字4ビットで符号化して、符号の長さは32ビットになる。 ハフマン符号については、出現頻度の低い2つを順次合併していくと、
| "A" = 3, "B" = 3, "C" = 2, "D" = 2 | → | "A" = 3, "B" = 3, "C" + "D" = 4 |
| → | "A" + "B" = 6, "C" + "D" = 4 | |
| → | ("A" + "B") + ("C" + "D") = 10 |
となる。
したがって、"A"は
00
, "B"は
01
, "C"は
10
, "D"は
11
と符号化し、全体では
00 00 00 01 01 01 10 10 11 11
と、符号の長さは20ビットになる。
次の文字列を固定長符号、ランレングス符号、およびハフマン符号で符号化し、符号の長さを比較してください。
今日の演習8の答案をメールで提出してください。 メールの差出人は学内のアドレス(b04a001@twcu.ac.jpなど)とし、メールの宛先はkonishi@twcu.ac.jpとします。 メールの本文には、学生番号、氏名、科目名、授業日(12月1日)を明記してください。