| 目次 | 索引 |
|---|---|
これまで文字列は、
int result = 12345679 * 9;
System.out.println("result: " + result);
のように画面出力のときのみ使ってきました。
実は、文字列は組み込みのクラスである
String
クラスのインスタンスです。
文字列はよく使われますので、便利な機能がいくつか用意されています。
まず、コンストラクタを使わなくてもインスタンスが生成できます。 コンストラクタを用いて
String s = new String(); s = "Good";
や
String s = new String("Good");
などと書かなくても、
String s = "Good";
でよいのです。
また、演算子
+
が使えます。
これは、文字列を連接します。
String s1 = "Good"; String s2 = "morning!"; String s3 = s1 + " " + s2;
としますと、
s3
には文字列 "Good morning!" が格納されます。
文字列と数を演算子
+
で結びますと、数が文字列に変換されてから連接されます。
int result = 12345679 * 9; String s1 = "result = "; String s2 = s1 + result;
としますと、
s2
には文字列 "result = 111111111" が格納されます。
String
クラスのメソッドで重要なものは以下の通りです。
charAt (int i)equals (String s)length ()valueOf (boolean b)valueOf (char c)valueOf (int i)
なお、メソッドを呼び出すときには、
char
や
int
などは書きません。
また、
static
と書いてあればクラスメソッド、書いてなければインスタンスメソッドです。
インスタンスメソッド
method
を呼び出すには、今まで通り
instance.method(argument...)
と書きます。 他のクラス class のクラスメソッド method を呼び出すには、
class.method(argument...)
と書きます。
文字列、すなわち
String
クラスのインスタンスは、一度生成されますとその内容は変更できません。
文字列 "Good morning!" の mor を eve に置き換えることができないのです。
内容を変更するには、文字列ではなく文字列バッファというものを用います。
文字列バッファ
(
string buffer
)
とは、組み込みのクラス
StringBuffer
のインスタンスのことです。
文字列バッファに対しては、文字の置き換え、追加、挿入などができます。
文字列を加工するには、いったん文字列バッファに変換し、処理のあと再び文字列に変換すればよいのです。
文字列を文字列バッファに変換するには、
StringBuffer
クラスのコンストラクタを用います。
逆に、文字列バッファを文字列に変換するには、インスタンスメソッド
toString()
を呼び出します。
String s1 = "Good morning!"; StringBuffer s2 = new StringBuffer(s1); s2.setCharAt(5, 'e'); s2.setCharAt(6, 'v'); s2.setCharAt(7, 'e'); String s3 = s2.toString();
としますと、
s3
には文字列 "Good evening!" が格納されます。
ここで、メソッド
void setCharAt (int i, char c)
は、そのインスタンスの i 番目の文字を c に置き換えるものです。
また、
StringBuffer
クラスについては以下の通りです。
append (String s)append (char c)charAt (int i)insert (int i, String s)insert (int i, char c)length ()setCharAt (int i, char c)toString ()
Integer
クラスでは、整数(
int
型)の変換に関するメソッドがいくつか提供されています。
その中では、以下のものが重要です。
parseInt (String s)int
型)に変換して返す。
toString (int i)int
型)を文字列に変換して返す。
ここで、コマンドライン引数から整数を一つ取り出すプログラム
/* 1*/ class FirstArgument /* 2*/ public static void main (String[] args) { /* 3*/ int x = Integer.parseInt(args[0]); /* 4*/ System.out.println(x); /* 5*/ } /* 6*/ }
b00a001@AsiaA1:~/java% java FirstArgument 100 100 b00a001@AsiaA1:~/java%
を思い出してください。 このプログラムの3行目の意味が、ここでやっと明らかになります。
このプログラムを実行しますと、変数
args
には文字列の配列が格納されます。
この配列は、
args[0]
がはじめのコマンドライン引数、
args[1]
が次のコマンドライン引数、…となるものです。
上記の場合では、
args[0]
に文字列 "100" が格納されます。
そして、クラスメソッド
parseInt
によって文字列 "100" が整数 100 に変換されます。
最後に、この整数 100 が変数
x
に格納されるのです。
前回説明した通り、文字は内部では整数として処理されます。
したがって、文字が等しいかどうかは、関係演算子
==
を用いて表します。
また、
>
や
<
などは、文字符号の大小関係を意味します。
例えば、
if (c == 'Z') {
...
}
は c が文字 Z ならば…ですし、
if (c > 'Z') {
...
}
は c の文字符号が Z の文字符号より大きいならば…です。
文字を1増加させることは、文字符号を1増加させることになります。 ただし、このことを
c = c + 1;
と書きますと、エラーになります。
これは、足し算によって右辺が整数(
int
型)と見なされるからです。
整数を文字に変換するには、
c = (char) (c + 1);
と書きます。 逆に、整数と見なされることを利用することもできます。 文字 c が数字である場合、式
c - '0'
はその数字の表す数になります。
文字に関するメソッドは、組み込みのクラスである
Character
クラスで提供されています。
この中で重要なものは以下の通りです。
isDigit (char c)isLowerCase (char c)isSpace (char c)isUpperCase (char c)toLowerCase (char c)toUpperCase (char c)文字列の応用例として、 ランレングス符号 ( run-length coding ) というデータ圧縮法を取り上げます。 ここでは、ランレングス符号を復号して、もとのイメージを画面に出力します。 なお、 復号 ( decode ) するとは 符号化 ( encode ) されたデータを元に戻すことです。 ランレングス符号は、ファックス伝送の基本にもなっています。 ファックス伝送の仕組みを簡単に紹介し、その中でランレングス符号について説明します。
ファックス伝送は、はじめに送信側が紙面イメージを読み込みます。 このとき、紙面イメージを75分の1インチ程度の単位で格子状に分割します。 そして、光学的な方法でそれぞれの升を白か黒かに決定します。 升を横にたどっていき、右端に達したら左端に戻るということを、紙面がつきるまで繰り返し、白黒の列を作ります。 最後に、この白黒データを受信側に送信します。
受信側では、まずこの白黒データを受け取ります。 そして、白黒データと一緒に紙面の升をたどっていき、データが黒ならばその部分を黒く記録します。 これを繰り返しますと、もとの紙面イメージができあがるのです。
ここで、白と黒をそれぞれ
W
と
B
で表わすことにしまして、送信側が白黒データ
WWWWWBBBBBBBWWWWWWWWWWWWWWWWWWWWWWWWWWWBBBBBWWWWWW
を構成したとします。
白黒データが長ければ長いほど、伝送に時間がかかりますので、なるべく短くしたいです。
そこで、5個の
W
、7個の
B
、27個の
W
、…、すなわち
5W7B27W5B6W
という符号化データを送ることにします。
これがランレングス符号です。
受信側では、
5W
を
WWWWW
に置き換え、
7B
を
BBBBBBB
に置き換え、…という復号操作を行ないますと、データを元に戻すことができます。
ランレングス符号は、同じ文字が何度も繰り返されるデータほど効果を発揮します。 なお、実際に圧縮する場合には、数の表現に工夫が必要です。
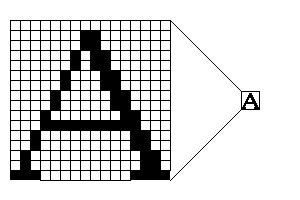
今、受信側がランレングス符号
16WE7W2B7WE7W2B7WE6W1B1W2B6WE6W1 B1W2B6WE5W1B3W2B5WE5W1B3W2B5WE4W 1B5W2B4WE4W1B5W2B4WE3W1B7W2B3WE3 W10B3WE2W1B9W2B2WE2W1B9W2B2WE1W1 B11W2B1WE1W1B11W2B1WE3B9W4BE
を受け取ったとします。
これを復号して、元の紙面イメージを画面に出力することが、このプログラムの目的です。
画面では、例えば白を
.
で、黒を
*
で表します。
なお、文字
E
は紙の右端を表すものとします。
画面では改行します。
アルゴリズムは次のようになります。
String
型の変数
code
を宣言し、受信した符号で初期化する。
プログラムは以下のようになります。
/* 1*/ class RunLength { /* 2*/ public static void main (String[] args) { /* 3*/ int i; /* 4*/ char c; /* 5*/ int times = 0; /* 6*/ String code = "16WE7W2B7WE7W2B7WE6W1B1W2B6WE6W1" /* 7*/ + "B1W2B6WE5W1B3W2B5WE5W1B3W2B5WE4W" /* 8*/ + "1B5W2B4WE4W1B5W2B4WE3W1B7W2B3WE3" /* 9*/ + "W10B3WE2W1B9W2B2WE2W1B9W2B2WE1W1" /* 10*/ + "B11W2B1WE1W1B11W2B1WE3B9W4BE"; /* 11*/ for (i = 0; i < code.length(); i++) { /* 12*/ c = code.charAt(i); /* 13*/ if (Character.isDigit(c)) { /* 14*/ times = times * 10 + c - '0'; /* 15*/ } else if (c == 'W') { /* 16*/ printChars('.', times); /* 17*/ times = 0; /* 18*/ } else if (c == 'B') { /* 19*/ printChars('*', times); /* 20*/ times = 0; /* 21*/ } else if (c == 'E') { /* 22*/ System.out.println(); /* 23*/ times = 0; /* 24*/ } else { /* 25*/ } /* 26*/ } /* 27*/ } /* 28*/ static void printChars (char c, int times) { /* 29*/ int i; /* 30*/ for (i = 0; i < times; i++) { /* 31*/ System.out.print(c); /* 32*/ } /* 33*/ } /* 34*/ }
b00a001@AsiaA1:~/java% java RunLength ................ .......**....... .......**....... ......*.**...... ......*.**...... .....*...**..... .....*...**..... ....*.....**.... ....*.....**.... ...*.......**... ...**********... ..*.........**.. ..*.........**.. .*...........**. .*...........**. ***.........**** b00a001@AsiaA1:~/java%
もう一つの応用例として、シーザー暗号を取り上げます。 シーザー暗号 ( Caesar cipher ) とはシーザー(カエサル)が用いたとされる暗号化の方法です。 また、 暗号化 ( encryption ) とは、秘密にしたいメッセージ( 平文 、 plaintext ) を特定の方法で第三者には読めない形式( 暗号文 、 ciphertext ) にすることです。
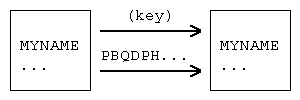
暗号を用いた通信は、一般的には次の通りです。 まず、メッセージの送信者は、暗号化の方法の他に、 鍵 ( key ) とよばれるデータを決定します。 そして、メッセージと鍵から暗号文を構成し、受信者に送信します。 受信者は、暗号化の方法とその鍵を知っています。 暗号文を受けとりますと、鍵を使って暗号文を元のメッセージに戻します( 復号 、 decryption )。 第三者は、暗号化の方法は知っていても鍵を知らないので、元のメッセージに戻すことが困難になります。 なお、鍵を使わずに元のメッセージに戻すことを 解読 ( cryptanalysis ) と言います。
ここでは簡単のため、平文はアルファベット大文字の並びとします。 また、スペースや各種記号は解読のヒントになりますので取り除いておきます。
シーザー暗号では、鍵 K は整数です。 平文のアルファベットを一文字ずつ K だけずらしたアルファベットに置き換えて、暗号化を行ないます。 例えば K = 3 でしたら、平文
MYNAMEISKYOKOAZUMA(私の名前は東京子です。)
は暗号文
PBQDPHLVNBRNRDCXPD
に暗号化されます。
アルファベットの置き換えは以下の表の通りです。
Y
が
B
に置き換えられることに注意してください。
| 平文 | A | B | C | D | E | F | G | H | I | J | K | L | M |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 暗号文 | D | E | F | G | H | I | J | K | L | M | N | O | P |
| 平文 | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 暗号文 | Q | R | S | T | U | V | W | X | Y | Z | A | B | C |
この表を逆にたどりますと復号ができます。 K = 26 - 3 = 23 としてもう一度暗号化することでも復号可能です。
なお、シーザー暗号はすぐに解読されます。 なぜならば、 K = 1 の場合、 K = 2 の場合、…、 K = 25 の場合をすべて確かめ、その中から意味の通るものを選べばよいからです。 ここでシーザー暗号を取り上げたのは、暗号の仕組みに慣れるためです。
アルゴリズムは次のようになります。
args[0]
で初期化する。
String
型の変数
plain
を宣言し、コマンドライン引数
args[1]
の平文で初期化する。
プログラムは以下のようになります。
/* 1*/ class CaesarCipher { /* 2*/ public static void main (String[] args) { /* 3*/ int i; /* 4*/ char c; /* 5*/ int key = Integer.parseInt(args[0]); /* 6*/ String plain = args[1]; /* 7*/ for (i = 0; i < plain.length(); i++) { /* 8*/ c = plain.charAt(i); /* 9*/ if (Character.isUpperCase(c)) { /* 10*/ c = (char) (c + key); /* 11*/ if (c > 'Z') { /* 12*/ c = (char) (c - 26); /* 13*/ } /* 14*/ } /* 15*/ System.out.print(c); /* 16*/ } /* 17*/ System.out.println(); /* 18*/ } /* 19*/ }
b00a001@AsiaA1:~% java CaesarCipher 3 MYNAMEISKYOKOAZUMA PBQDPHLVNBRNRDCXPD b00a001@AsiaA1:~% java CaesarCipher 23 PBQDPHLVNBRNRDCXPD MYNAMEISKYOKOAZUMA b00a001@AsiaA1:~%
最後の例は探索です。 探索 ( search )とは、データのかたまりの中から、要求されたデータの位置を特定し、その位置のデータを取り出すことです。 ここでは、文字列
MYNAMEISKYOKOAZUMA
から文字を探索し、その位置を求めます。 入力された文字を、文字列の0番目の文字、1番目の文字、…と順番に比較し、一致したらそこで終了します。 最後まで一致しなかったら、文字がないと答えます。
なお、このような、最初から順番に調べる探索法は、 線形探索 ( linear search )とよばれます。 線形探索では、データが存在しないと結論づけるためには、すべてのデータを調べなくてはなりません。 また、同じデータが複数ある場合、最初のデータが取り出されます。
アルゴリズムは次のようになります。
String
型の変数
str
を宣言し、初期値を"MYNAMEISKYOKOAZUMA"とする。
char
型の変数
c
を宣言する。
return
文で終了する。
プログラムは以下のようになります。
/* 1*/ import java.io.*; /* 2*/ /* 3*/ class LinearSearch { /* 4*/ public static void main (String[] args) throws IOException { /* 5*/ InputStreamReader isr = new InputStreamReader(System.in); /* 6*/ BufferedReader br = new BufferedReader(isr); /* 7*/ String str = "MYNAMEISKYOKOAZUMA"; /* 8*/ int pos = 0; /* 9*/ char c; /* 10*/ System.out.print("Enter a character: "); /* 11*/ c = (char) br.read(); /* 12*/ while (pos < str.length()) { /* 13*/ if (str.charAt(pos) == c) { /* 14*/ System.out.println(pos); /* 15*/ return; /* 16*/ } else { /* 17*/ pos++; /* 18*/ } /* 19*/ } /* 20*/ System.out.println("Not found."); /* 21*/ } /* 22*/ }
b00a001@AsiaA1:~/java% java LinearSearch Enter a character: N 2 b00a001@AsiaA1:~/java% java LinearSearch Enter a character: A 3 b00a001@AsiaA1:~/java% java LinearSearch Enter a character: P Not found. b00a001@AsiaA1:~/java%
整列された文字列の中から文字を二分探索してください。
辞書が能率よく引けるのは、単語が整列されているからと、引くときに二分探索のようなことを行っているからです。 二分探索 ( binary search )の考え方は次の通りです。 まず、しおりを2つ用意します。 一方を左しおりとよび、他方を右しおりとよびます。 始めに、左しおりを辞書の左端に挟み、右しおりを辞書の右端に挟みます。 そして、左しおりと右しおりの真ん中のページを開きます。 もしそのページに探索語があれば探索終了です。 探索語がそのページより左にある場合は、右しおりをそのページの1つ左に挟みます。 探索語がそのページより右にある場合は、左しおりをそのページの1つ右に挟みます。 再び左しおりと右しおりの真ん中のページを開きます。 この作業を繰り返し、もし左しおりが右しおりより右に挟まれたときは、探索語がないと答えて探索終了です。
本来は文字列の列の中から文字列を探索すべきですが、問題を簡単化して、文字列の中から文字を探索します。 辞書の頭文字だけを考えていると思ってもよいです。
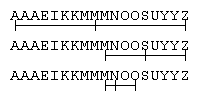
アルゴリズムは次のようにします。
String
型の変数
sorted
を宣言し、初期値を"AAAEIKKMMMNOOSUYYZ"とする。
char
型の変数
c
を宣言する。
return
文で終了する。
このアルゴリズムをプログラムにしてください。
b00a001@AsiaA1:~/java% java BinarySearch Enter a character: N 10 b00a001@AsiaA1:~/java% java BinarySearch Enter a character: A 1 b00a001@AsiaA1:~/java% java BinarySearch Enter a character: P Not found. b00a001@AsiaA1:~/java%
余力のある人は、文字列の中に探索文字が複数ある場合に、最も左のものを選ぶようにしてください。
b00a001@AsiaA1:~/java% java BinarySearch2 Enter a character: N 10 b00a001@AsiaA1:~/java% java BinarySearch2 Enter a character: A 0 b00a001@AsiaA1:~/java% java BinarySearch2 Enter a character: P Not found. b00a001@AsiaA1:~/java%
今日の演習12に従ってJavaプログラムを作成し、そのプログラムをkonishi@twcu.ac.jpあてにメールで提出してください。 メールには、学生番号、氏名、科目名、授業日(12/11)を明記してください。