| 目次 | 索引 |
|---|---|
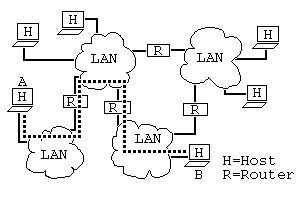
インターネット ( the Internet )とは、世界中の組織のネットワークどうしを相互接続して構成された、世界規模のネットワークです。 インターネットと対比して、組織内のネットワークを LAN (Local Area Network)とよびます。
ネットワークに接続しているコンピュータを ホスト ( host )とよびます。 ネットワークを相互接続する機器を ルータ ( router )とよびます。
今、インターネットを経由して、ホスト A からホスト B へデータを伝送したいとします。 ホスト B がホスト A と同一のネットワークにあるときは、データは直接ホスト B に伝送されます。 そうでなければ、データはルータ R1 に伝送されます。 それぞれのルータには、 経路表 ( routing table )とよばれるリストが格納されています。 ルータ R1 では、経路表にしたがって、ホスト B にたどり着きそうなルータ R2 が決定されます。 そして、データはルータ R1 から R2 に伝送されます。 ルータ R2 でも、経路表にしたがってルータ R3 が決定され、データは R3 に伝送されます。 いくつかのルータを経由して、やがてデータはホスト B のあるネットワークにたどり着きます。 最後に、ホスト B にデータが伝送されます。
前回は、IPアドレスの割り当てについて説明しました。 組織(ネットワーク)ごとに、IPアドレスの範囲を割り当てるというものでした。 この仕組みは、ルータの経路表でも利用されます。
ネットワークアドレス ( network address )とは、(代表)IPアドレスと固定ビット数をスラッシュ(/)で区切った表現です。 これは、前回紹介したネットマスクと同様の役割を果たします。
例えば、仮に東京女子大学のネットワークが、202.11.169.0から202.11.169.255までの範囲のIPアドレスを割り当てられているとします。 このネットワークのネットマスクは255.255.255.0です。 最初の24ビットが固定ということですので、このネットワークのネットワークアドレスは202.11.169.0/24となります。
ネットワークアドレスとホストのIPアドレスを比較しますと、そのホストがそのネットワークのものかどうかが分かります。 また、データの行き先が同じネットワークのホストでしたら、伝送するルータも同じです。 従って、経路表は、データの行き先がホスト H1 ならばルータ R1 へ、ホスト H2 ならばルータ R2 へ、…といった巨大なリストである必要がなくなります。 ネットワークアドレスを登録することにより、データの行き先がネットワーク N1 ならばルータ R1 へ、ネットワーク N2 ならばルータ R2 へ、…といったコンパクトなリストにできるのです。
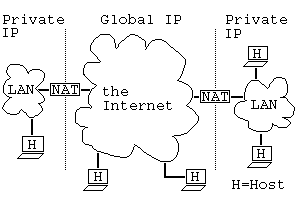
東京女子大学に割り当てられているIPアドレスの範囲が、仮に前述の通りだとしますと、学内には254台しかホストが置けないことになります。 この問題は、プライベートIPアドレスを用いると解決できます。 プライベートIPアドレス ( private IP address )とは、以下の特別な範囲の中のIPアドレスです。
| IPアドレス | ネットマスク |
|---|---|
| 10.0.0.0 | 255.0.0.0 |
| 172.16.0.0 | 255.240.0.0 |
| 192.168.0.0 | 255.255.0.0 |
プライベートIPアドレスでないIPアドレスは、 グローバルIPアドレス ( global IP address )とよばれます。
プライベートIPアドレスは、IPアドレスの管理組織に割り当てられなくても自由に使えるIPアドレスです。 ただし、そのまま使いますと、インターネットでIPアドレスが重複する可能性があります。 一般的には、組織を代表するホストにグローバルIPアドレスを割り当て、その他のホストにプライベートIPアドレスを割り当てます。 組織内で通信するときは、プライベートIPアドレスは重複しませんので、とくに工夫は要りません。 組織外と通信するときは、ルータがプライベートIPアドレスをグローバルIPアドレスに変換し、あたかもグローバルなホストが通信しているように見せます。 (このようなルータは、NAT(Network Address Translator)とよばれます。) このようにしますと、たとえ同じプライベートIPアドレスが複数の組織で使われていましても、変換後のグローバルIPアドレスは異なりますので、通信に混乱は生じないのです。
インターネットで伝送されるデータは、 パケット ( packet )とよばれる単位を持っています。 つまり、(大きな)データを伝送するとき、送信側のソフトウェアはデータをそのまま送信するのではなく、データをパケットに分割し、一つ一つのパケットを送信します。 そして、受信側のソフトウェアは、受信したパケットを統合し、元のデータに復元するのです。
データをパケットに分割することにより、インターネットが誰かに占有されることがなくなります。 もし、巨大なデータがそのまま送信されたならば、ルータは長い時間をかけてそのデータを伝送することになります。 その間、他のデータは受け付けられませんので、長い時間にわたって他のデータが伝送できなくなってしまいます。 巨大なデータをたくさんのパケットに分割すれば、ルータはそれらのパケットを伝送するすきに、他のデータ(のパケット)を伝送できるのです。
IPアドレスのところで説明しましたが、 プロトコル ( protocol )とは、通信規約のことです。 ホームページが見られるのは、HTTPとよばれるプロトコルに基づいて通信が行われているからです。 ただし、HTTP自身は、ホームページの内容を電気信号に置き換える規約ではありません。
プロトコルにはいくつかの階層があります。 最も上位の階層はアプリケーション層とよばれ、ソフトウェアに依存する部分の規約を定めています。 (HTTPはここのプロトコルです。) 最も下位の階層は物理層とよばれ、電気信号に関する規約を定めています。 アプリケーション層と物理層の間には複数の階層があり、パケットをやり取りするための規約が段階的に定められています。 それぞれの階層のプロトコルに従って、ホームページの内容がパケットに置き換わり、そして電気信号に置き換わるのです。
プロトコルを階層化する利点は、プロトコルの変更がしやすくなることです。 例えば、銅線ではなく光ファイバによる通信を開始する場合、光信号に置き換えるための物理層のプロトコルだけが用意されます。 アプリケーション層のプロトコルであるHTTPは、たとえ銅線から光ファイバに変わっても、そのまま使えるのです。
コンピュータは、ソフトウェアが稼働してはじめて機能することに注意してください。 ホスト A からホスト B にデータが伝送されるのは、ホスト A で稼働しているソフトウェアが、ホスト B で稼働しているソフトウェアにデータを伝送しようとするからです。
データを伝送するソフトウェアには、データを提供することが主であるソフトウェアと、データを要求することが主であるソフトウェアがあります。 提供する側のソフトウェアを サーバ ( server )とよび、要求する側のソフトウェアを クライアント ( client )とよびます。
ここで、ルータは単にデータを交換しているだけであることに注意してください。 インターネットでデータを処理するのは、ホストで稼働しているソフトウェアなのです。
ホストとサーバは、しばしば同一視されますが、この授業ではできるだけ区別します。 ホストはコンピュータ(ハードウェア)で、サーバはソフトウェアなので、確かに別物です。 しかし、区別する本当の理由は、通常一つのホストの上で複数のサーバが稼働しているからです。
パケットとは、インターネットで伝送されるデータの単位でした。 パケットは、制御データ(ヘッダとよばれる)と伝送データから構成されます。 ヘッダには、宛先のIPアドレスと、ポート番号とよばれる数値が含まれます。 ルータは、ヘッダの宛先IPアドレスを見て、パケットを適切なホストに向けて伝送します。 ポート番号 ( port number )とは、サーバなどの伝送先ソフトウェアを区別する番号です。 ホストに届いたパケットは、ポート番号に従って、適切なソフトウェアで処理されます。 IPアドレスとポート番号によって、伝送先のホストとソフトウェアが決定されるのです。
はじめに紹介するサーバは、 DHCP (Dynamic Host Configuration Protocol)サーバです。 これは、使われていないIPアドレスを動的に割り当てるソフトウェアです。 プロバイダ経由でパソコンをインターネットに接続する際によく使われます。
買ってきたばかりのパソコンには、IPアドレスは割り当てられていません。 プロバイダと契約しても、普通はIPアドレスは指定されません。 しかし、パソコンにはDHCPクライアントにあたるソフトウェアが組み込まれています。 パソコンをプロバイダに接続するとき、このDHCPクライアントが稼働します。 DHCPクライアントは、DHCPサーバに対してIPアドレスの割り当てを要求します。 DHCPサーバは、この要求に応じ、その時点で未使用のIPアドレスを選び、DHCPクライアントに返答します。 そして、DHCPクライアントはこのIPアドレスをもとにパソコンの設定を行います。 IPアドレスが割り当てられたので、このパソコンはインターネットを構成するホストになり、インターネット上のサービスが利用できるわけです。
次に紹介するサーバは、 DNS (Domain Name System)サーバです。 DNSサーバは、ネームサーバともよばれます。 これは、ドメイン名からIPアドレスを割り出すソフトウェアです。 DNSの働きによって、IPアドレスだけではなく名前によってもホストが指定できます。
ドメイン名からIPアドレスを割り出すには、どこかのホストにその対応表を登録しておけばよさそうです。 しかし、ドメイン名をどうつけるかは、基本的に各ドメインの管理組織に委任されていますから、その対応表もドメインごとに設置されることになります。 このばらばらの対応表を組み合わせ、ドメイン名からIPアドレスを割り出す(名前解決といいます)仕組みがDNSです。
例えば、情報処理センターで、Netscapeの「場所:」入力欄に
http://www.usyd.edu.au/
と入力したとします。 このとき、NetscapeはDNSクライアントの機能を働かせて、ドメイン名www.usyd.edu.auの名前解決を行うわけですが、名前解決までには次のようなやり取りが行われます。 ここで、ルートドメインとは木の根にあたるドメインです。
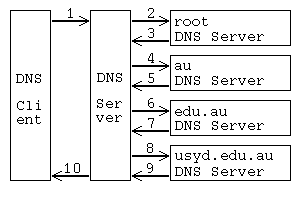
ドメインの階層の上から順番に解決していることに注意してください。 ただし、このやり取りは最悪の場合です。 実際には、情報処理センターのDNSサーバがauドメインのDNSサーバのホストのIPアドレスを知っていたり、auドメインのDNSサーバがusyd.edu.auドメインのDNSサーバのホストのIPアドレスを知っていたりしますので、もっと能率よく名前解決が行われます。
最後に紹介するサーバは、 WWW (World Wide Web)サーバです。 WWWサーバは、ウェブサーバともよばれます。 これは、URLによって指定されるHTMLドキュメントなどを転送するソフトウェアです。 WWWクライアントにあたるソフトウェアは、NetscapeなどのWWWブラウザ(ウェブブラウザ)です。 つまり、Netscapeがデータを要求し、それに応じてWWWサーバがデータを提供するわけです。
例えば、情報処理センターでシドニー大学のホームページを見ようとして、Netscapeの「場所:」入力欄に
http://www.usyd.edu.au/
と入力したとします。 このときNetscapeは、シドニー大学のホストで稼働しているWWWサーバにむけて、要求データ(このURL)を送信します。 いくつかのルータを経由して、WWWサーバは要求データを受信します。 WWWサーバは、要求データを処理し、提供データ(シドニー大学のホームページのHTMLドキュメント)を決定します。 そして、情報処理センターのホストで稼働しているNetscapeにむけて、提供データを送信します。 再びいくつかのルータを経由して、Netscapeは提供データを受信します。 Netscapeは、提供データを処理し、シドニー大学のホームページを描画します。
以前、ホームページが見られるのは、HTTPとよばれるプロトコルに基づいて通信が行われるからだと説明しました。 HTTP (HyperText Transfer Protocol)とは、WWWサーバとブラウザの間のプロトコルです。 HTTPの仕組みは単純です。
これだけです。 このやり取りを何度か繰り返して、ブラウザはホームページの表示に必要なデータを集めます。
なお、ブラウザへ送られるファイル情報の中では、ファイルの種類が重要です。 HTML形式のファイルを転送すときには、ファイル情報の中で
Content-Type: text/html
という文字列が送られます。 JPEG形式のイメージのときには、
Content-Type: image/jpeg
という文字列が送られます。 ブラウザは、受け取ったファイル情報をもとに、テキストファイルの場合、イメージファイルの場合と、適切な処理を行います。
シドニー大学のホームページ
http://www.usyd.edu.au/index.html
の内容が、仮に
<html>
<head>
<title>The University of Sydney</title>
</head>
<body>
<div>
<img src="images/logo.gif"
alt="The University of Sydney"
width="500" height="50">
</div>
...
</body>
</html>
であるとします。 (実際はもっと複雑です。) Netscapeでシドニー大学のホームページを見た場合、Netscapeとシドニー大学のホストのWWWサーバとの間では、おおよそ次のようなやり取りが行われます。
というイメージファイルの指定があるので、この相対URLを解決し、絶対URL<img src="images/logo.gif"...>
http://www.usyd.edu.au/images/logo.gifを得る。
ロボット系検索エンジンでは、検索語を入力しますと、しばらくして検索語に関するホームページが表示されます。 実は、検索語ごとにHTMLファイルがあらかじめ用意されているわけではありません。 検索エンジンのプログラムは、検索語などのデータを受け取りますと、データベースに基づいて検索語に関する情報を集め、その場でHTMLドキュメントを合成し、それをブラウザに転送しているのです。 このようなプログラムは、一般に CGI (Common Gateway Interface)プログラムとよばれます。
ネットワークの仕組みについて、以下の問いに答えなさい。
問1. IPアドレスのIPとは何の略ですか。
問2. IPアドレスは何ビットで構成されますか。 (IPのバージョンは4とします。)
問3. ドメイン名の説明について適切なものを次から選びなさい。
問4. トップレベルドメインに関する説明のうち、適切でないものを選びなさい。
問5.
http://www.twcu.ac.jp/cis/
のように、ディレクトリ名で終わるURLを指定してWWWブラウザで開くとどうなりますか。 次のうち、適切でないものを選びなさい。
問6. ファイル
/home/b00a/b00a001/WWW-local/trip/trip.html
から
/home/b00a/b00a001/WWW-local/trip/hyogo/kobe.html
へリンクを張りたいとします。
trip.html でどう指定したらよいですか。
次から適切なものを選びなさい。
(
<base>
タグはないものとします。)
<a href="trip/hyogo/kobe.html">神戸へ</a>
<a href="hyogo/kobe.html">神戸へ</a>
<a href="../hyogo/kobe.html">神戸へ</a>
<a href="../kobe.html">神戸へ</a>
問7. ルータについて適切な説明を次から選びなさい。
問8. DNSサーバの機能について適切な説明を次から選びなさい。
問9. WWWはクライアント・サーバ・モデルに基づいていますが、これについて適切な説明を次から選びなさい。
問10. イメージ(画像)が埋め込まれたホームページを開くとき、ネットワークではどのようにファイルが転送されますか。 適切な説明を次から選びなさい。
今日の演習11の解答をkonishi@twcu.ac.jpあてにメールで送ってください。 メールには、学生番号、氏名、科目名、授業の日付け(6/19)を明記してください。