Canonical deep neural networks
深層ニューラルネットワークとは何か
2層以上の中間層を持つニューラルネットワークを深層ニューラルネットワーク と呼びます。
\begin{equation}
h_1 = \sigma\left(\mathbf{W}_1\mathbf{x}+\mathbf{b}_1\right)
\end{equation}
\begin{equation}
h_2 = \sigma\left(\mathbf{W}_1\mathbf{h}_1+\mathbf{b}_2\right)
\end{equation}
\begin{equation} P = \mbox{softmax}\left(\mathbf{W}_{o}+\mathbf{b}_o\right) \end{equation}
活性化関数 activation function にはロジスティック関数 logistic function が 使われてきました
\begin{equation} \sigma(x) = \frac{1}{1+e^{-x}} \end{equation}
英語で S 字曲線の意味を持つシグモイド関数 sigmoid function という 言葉も用いられます。次のハイパータンジェントもシグモイド関数 です。 \begin{equation} \phi(x) = \tanh(x) = 2\sigma(2x) - 1. \end{equation}
近年ではより簡単な非線形関数を用いる傾向が あります。 ReLU など。 \begin{equation} ReLU = \max(0, x) \end{equation}
出力層における誤差,あるいは損失を参照にするような学習が行われます。 例えば損失としてクロスエントロピー cross entropy を用いることに すれば \begin{equation} l(t,y) = \mathbf{t}^T\log\left(\mathbf{y}\right) \end{equation} あるいは次のように表記します。 \begin{equation} l(t,y)=-\sum_{i=1}^{m}\left[t_{i}\log(y_{i})+(1-t_{i})\log(1-y_{i})\right] \end{equation}
回帰ではなくクラス分類の場合にはクロスエントロピー損失を用いることが 多いです。理由は [ニールセンのブログ]((http://neuralnetworksanddeeplearning.com/chap3.html) にも詳細に記述されています。 和訳 またングのビデオ講義ロジステック回帰の説明に詳しいです。
主要パッケージでの関数
-
TensorFlow
Python tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, name=None) -
Chainer
Python chainer.functions.softmax_cross_entropy(x, t, use_cudnn=True, normalize=True, cache_score=True) -
Theano
Python theano.tensor.nnet.nnet.categorical_crossentropy(coding_dist, true_dist)
再帰型ニューラルネットワーク RNN: recurrent neural networks
再帰型ニューラルネットワークとは,系列処理に用いられます。 時刻 $t$ と再帰結合(時間遅れの結合)を導入して
\begin{equation}
h_1(t) = \sigma\left(\mathbf{W}_1\mathbf{x}(t) + h_1(t-1) + \mathbf{b}_1\right)
\end{equation}
\begin{equation}
h_2(t) = \sigma\left(\mathbf{W}_1\mathbf{h}_2(t)+h_2(t-1) + x\mathbf{b}_2\right)
\end{equation}
\begin{equation} P(t) = \mbox{softmax}\left(\mathbf{W}_{o}(t)+\mathbf{b}_o\right) \end{equation} となります。
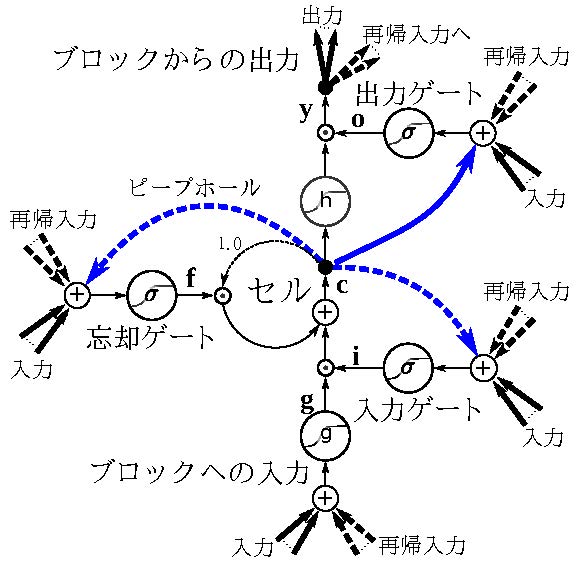
近年では機械翻訳,対話,文章生成,画像の説明文生成など 多くの応用分野を持ちます。 ほとんどが 長 短期記憶 LSTM: long short-term memory と呼ばれる モデルを用いてます。